Text Mining技術淺談
作者:李慶堂 / 臺灣大學計算機及資訊網路中心程式設計組幹事
資料探勘(Data Mining)與文字探勘(Text Mining)關係緊密,相較於前者顯著的結構化,後者長短不一、沒有規律,且尚有現今生活中隨口說出來的字彙,或是從社群網站、BBS衍生出的用語,隨著使用者每天更新及增減而無法事先定義。近10年搜尋引擎的崛起,有效運用、改善文字探勘技術,並創造其新的價值。本文將簡單介紹文字探勘在搜尋引擎中的定位,以及技術的核心概念。
近年來,無論是產業界或是學術界的研究單位均針對巨量資料(Big Data)與資料探勘(Data Mining)投入大量的資源,希望能透過這些技術從大量資料中取得傳統方式無法取得的推論,從而運用於營運以提昇收益或取得新發現。
而資料探勘(Data Mining)與文字探勘(Text Mining)兩者關係相當緊密。以資料探勘來說,基本上它是以顯著的結構化,像是有規律且有結構的表格、資料庫,每一表格內的數值或是參數都已經事先由設計者定義好,只需依照需求者所需的資訊,利用相關語法或是事先定義的規則,即可得到結果。那文字探勘它有規則嗎?其實它是沒有任何的規則、有長有短、毫無可定義的原始資料,它只是我們周遭日常生活中所講出來,或是由某些關係而衍生出來的文字或句子。像是現今生活當中,常會聽到以前沒聽過,但現在經常隨口說出來的文字是由網路上的社群網站、BBS或其他智慧型手持式裝置所產生出來的用語,例如:BBS所使用的語言、社群網站使用語言,手持式行動裝置使用語言…等等,毫無整理過的文字可能會隨著使用者每天不斷的更新、發表與增減。這些種種的文字其實可以是毫無意義,也可以試著利用一些方式或是統計而把它變成資源,進一步達到文字探勘的目標。
隨著這近10年間,搜尋引擎的方便性及準確性,又以搜尋引擎龍頭Google的崛起,其顛覆了傳統邏輯思維,改寫了資訊檢索的不變定律,創造其新的價值。開發者對於使用者的需求,只需要輸入相關關鍵字,即可搜尋到符合之文字或網頁,隨著時間不斷的累積,其索引不斷的建立,進一步能將搜尋引擎技術中,除了實現網頁搜尋、圖片搜尋外,更能完善相關核心技術:
● 網路爬蟲
● 語言分詞
● 排序演算法
● 文字探勘相關
● 巨量數據存儲
● 分佈式計算
搜尋引擎與文字探勘兩者之間的關係
通用的搜尋引擎系統流程:
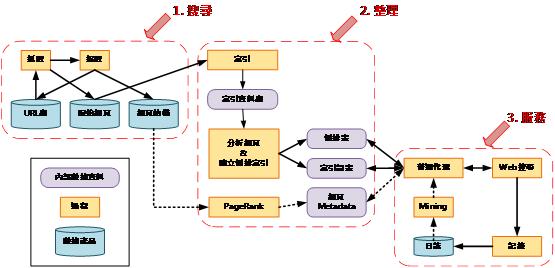
圖一
使用者將文件或文字透過搜尋引擎進行索引之後,存放於索引資料庫中,累積成文字探勘的基礎。搜尋引擎不僅提供全文搜尋、模糊搜尋、關鍵字搜尋等功能,在我們需要做文字探勘時,也可以以搜尋引擎為基礎發展出多種文字探勘的功能。

圖二
搜尋引擎中文字探勘常會遇到的典型問題:
● 要怎麼樣找到一篇文章或網頁其關鍵字、圖片、主題
● 要怎麼樣使用數學公式來識別文章或網頁
● 要怎麼樣處理關鍵字及文章的相似度確認
● 要怎麼樣處理多份文章的相似度
把每個文件看做為一整串的索引(Index Term)所組成,而每一個詞都有權重,不同的索引詞根據自己在文件中的權重進而影響文件相關性的評分計算,看做成一個n維向量,來證明該文件中向量集合,查詢及文件都可以轉化為索引詞及權重所組成的向量空間模型VSM (Vector Space Model)。
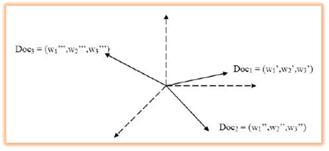
圖三
另外,常在做文字探勘時,經常會使用綜合評比的方式,當搜尋某一個詞Ti在多數文件{D1, D2, …Dn}出現的頻率,就可以算出來,當出現越多次其權重越高,反之則低。假設Tx在Dy的文件出現的頻率,可稱之Tx在Dy的詞頻TF(Term Frequency)。
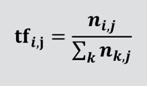
圖四
而當{D1, D2, …Dn}的文件集合中,有包含Ti的出現的頻率,稱之文件頻率DF(Document Frequency),相反,如果需要知道其普遍重要性的度量,則為反向文件頻率IDF(Inverse Document Frequency)。
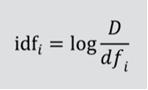
圖五
雖然可以利用詞頻TF計算出來詞出現的頻率,但卻會發生詞A只出現在特定文件中,另一詞B卻只出現在另一些文件中。當同時在特定文件,其出現的頻率都相同則無法判斷A或B的權重,故為此而衍生出來一種TF-IDF(Term Frequency- Document Frequency),把詞頻TF及反向文件頻率IDF做結合,產出高權重的TF-IDF。藉TF-IDF可以過濾掉常見詞語,保留重要詞語
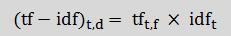
圖六
社群中發表一份文章或言論,只要有人按讚或是分享出去,這時候系統就開始做關聯。另外像是當某些網站需要與社群網站做關聯提取資料時,常會跳出需要提供相關資料供參考,就可以從中發現到有結構化或沒有結構化的資料在每日不斷的產出,研究單位就可以針對所需要的資訊進行分析探勘,以得到所需的結果。
最後提供文字探勘Text Mining相關開放原始碼的項目可供參考:
● 數據探勘(Data Mining):Weka、R-Project
● 文字探勘(Text Mining):OpenNLP、LingPipe、FreeLing
● 推薦引擎相關:Apache Mahout、Duine framework、Singular Value Decomposition (SVD)
● 搜索引擎相關:Lucene、Solr、Sphinx、Hibernate Search等
參考資料
Text-mining
http://en.wikipedia.org/wiki/Text_mining
TF-IDF
http://zh.wikipedia.org/wiki/TF-IDF
IThome 從搜尋引擎到文字探勘
http://www.ithome.com.tw/voice/90361 |