文字探勘之前處理與TF-IDF介紹
作者:楊德倫 / 臺灣大學計算機及資訊網路中心教學研究組幹事
在瞬息萬變的網路世界,如果對於這些數位內容沒有即時加以整理或蒐集,就可能錯過許多珍貴而值得關注的資料與訊息。有鑑於此,為了處理非結構化的資訊(如大量的客戶意見資料、電子郵件的內文等),透過某些統計方法和演算法(如將文字量化、轉換為有意義的數字)來進行分析,進而取得重要的參考資料或可提供決策分析的數據,此時,Text Mining便成為當今的熱門話題。
前言
Text Mining 是以各種 Data Mining 方式來進行文件的文字資料分析,透過其分析來取得文字間的關聯性。與 Data Mining 不同之處,在於 Text Mining 是針對文字進行分析,且文字多屬半結構化或非結構資料,因此要先對文字進行前處理(Pre-Processing),並透過某些統計方法與演算法(例如:Term Frequency - Inverse Document Frequency,簡稱 TF-IDF),對文字進行分析與運用,進而取得必要的資訊,作為決策的參考依據。
前處理程序
Text Mining 的前處理程序如下:
1. Part-of-Speech Tagging:
首先進行詞性分析,包括前後詞判斷,以及同義字(Synonym)、一字多義字(Polysemy)、反義字(Antonym)、泛稱(Hypernym)、具體名稱(Hyponym)…等;而單字可能與前後文字組成單詞(例如勞「作」、「作」業、工「作」、杵「作」、「作」文、磨杵「作」針等),因此 Text Mining 需要詞庫來進行標記(Tagging)處理。
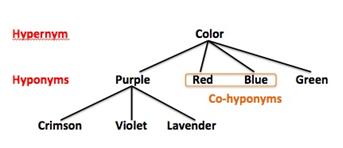
圖一 泛稱與具體名稱之間的關聯(圖片取自維基百科)
2. Stemming:
透過移除單字的後綴(例如:cats、catlike、catty,皆是以cat作為基礎,fishing、fished、fisher則以fish作為基礎),將字根進行還原。
3. Feature Selection:
將擷取出來的單詞(Terms)進行過濾與篩選,首先決定保留哪些詞性的單詞(例如動詞或名詞),而後透過 TF-IDF 等統計方法或演算法,來分析單詞的頻率。
介紹 TF-IDF(Term Frequency - Inverse Document Frequency)
TF-IDF 是一種用於資訊檢索與文字探勘的常用加權技術,為一種統計方法,用來評估單詞對於文件的集合或詞庫中一份文件的重要程度,筆者在此介紹如下:
1. TF(Term Frequency):
假設 j 是「某一特定文件」,i 是該文件中所使用單詞或單字的「其中一種」,n(i,j) 就是 i 在 j 當中的「出現次數」,那麼 tf(i,j) 的算法就是 n(i,j) / (n(1,j)+n(2,j)+n(3,j)+…+n(i,j))。例如第一篇文件中,被我們篩選出兩個重要名詞,分別為「健康」、「富有」,「健康」在該篇文件中出現 70 次,「富有」出現 30 次,那「健康」的 tf = 70 / (70+30) = 70/100 = 0.7,而「富有」的 tf = 30 / (70+30) = 30/100 = 0.3;在第二篇文件裡,同樣篩選出兩個名詞,分別為「健康」、「富有」,「健康」在該篇文件中出現 40 次,「富有」出現 60 次,那「健康」的 tf = 40 / (40+60) = 40/100 = 0.4,「富有」的 tf = 60 / (40+60) = 60/100 = 0.6,tf 值愈高,其單詞愈重要。
所以,「健康」對第一篇文件比較重要,「富有」對第二篇文件比較重要。若搜尋「健康」,那第一篇文件會在較前面的位置;而搜尋「富有」,則第二篇文章會出現在較前面的位置。
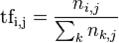
圖二 tf 的數學表達方式(圖片取自維基百科)
2. IDF(Inverse Document Frequency):
換個角度來看,假設 D 是「所有的文件總數」,i 是網頁中所使用的單詞,t(i) 是該單詞在所有文件總數中出現的「文件數」,那麼 idf(i) 的算法就是 log ( D/t(i) ) = log D – log t(i)。例如有 100 個網頁,「健康」出現在 10 個網頁當中,而「富有」出現在 100 個網頁當中,那麼「健康」的 idf = log ( 100/10 ) = log 100 – log 10 = 2 – 1 = 1,而「富有」的 idf = log (100/100) = log 100 – 1og 100 = 2 – 2 = 0。
所以,「健康」出現的機會小,與出現機會很大的「富有」比較起來,便顯得非常重要。

圖三 idf 的數學表達方式(圖片取自維基百科)
3. 最後,將 tf(i,j) * idf(i)(例如:i =「健康」一詞)來進行計算,以某一特定文件內的高單詞頻率,乘上該單詞在文件總數中的低文件頻率,便可以產生 TF-IDF 權重值,且 TF-IDF 傾向於過濾掉常見的單詞,保留重要的單詞,如此一來,「富有」便不重要了。
常見應用
1. 分析開放式調查研究的回應結果:
常見於行銷方面,其觀點在於允許回應者在不受特定面向與回應格式的侷限,來表達他們自身的觀點與意見。例如使用者在填寫問卷後,透過在單詞上的使用,來分析他們對產品或服務的評價與感受,來為其體驗上的不足、誤解以及困惑,提供建議與解答,同時分析其消費行為,進一步做到客戶分群,並擬定及提供客製化的服務給消費者。
2. 如同訊息、電子郵件等格式的自動化處理:
例如過濾客戶的意見回饋,來了解信件的內容是正面或負面的評價,或是過濾電子郵件,來了解是否為垃圾郵件,若是合法郵件,也可自動分析此信件的訴求是屬於哪個部門該處理的業務範圍。
3. 分析產品保固、保險金請求,以及診斷面談等內容:
在保固期間內,若產品有非人為因素的損壞,通常可以依保固項目來進行送件維修,送件時需要填寫一份維修單,廠商會透過使用者的口述來進行損壞原因註記,透過註記的電子化與分析,為產品日後改版或強化,提供很好的建議;在保險金請求時,保險業者會進行記錄,並將請求內容進行分析,作為日後提供保險服務的依據與參考;透過與病人會晤與交談,了解病患的需求與病癥,進而分析成有用的資訊,作為日後提供診療的參考。
4. 經由網路爬蟲(Crawler)來擷取、調查競爭對手的網站:
前往競爭對手的主要網站,來「爬」遍所有的內容,自動建立可用的單詞與文件列表,為他們所描述和強調的部分進行探勘,便能輕易地取得競爭對手有價值的商業智慧與邏輯。
後記
現今應用 Text Mining 所創造出來的產值,已超過過去以資料庫搜尋為主的價值。在網際網路以非常快速的方式,所累積愈來愈多非結構化資料的趨勢下,實際運用 Text Mining 來探索出各種未能預見、創新、重要的資訊或知識,如商品評價、施政評價、民意調查、社群偏好等等,對政府機關、企業團體或個人而言,都是非常重要的工作,Text Mining 的相關研究和實作,已成為晚近最為熱門的話題。
參考資料
TF-IDF
http://zh.wikipedia.org/wiki/TF-IDF
Text Mining (Big Data, Unstructured Data)
http://www.statsoft.com/Textbook/Text-Mining
Hyponymy and hypernymy
http://en.wikipedia.org/wiki/Hyponymy_and_hypernymy
|