首頁 >專題報導
Deep Learning與影像風格轉換
雖然人工智慧(Artificial Intelligence)在過去十年之間有了全然不同的突破和發展,但讓電腦進行藝術創作一直是人工智慧領域的一個大難題。以繪畫為例,人類畫家可以結合內容(content)和風格(style)等不同的元素,產生出獨特的視覺體驗。在過去也曾有研究使用演化式計算(Evolutionary Computation)或其他自動化的演算法來產生出視覺藝術或作曲,這樣的研究領域稱為生成藝術(Generative art),但電腦自動產生的結果還是跟人類有蠻大的差距,尤其是在理解風格這類抽象的概念,電腦更是不容易做到。然而類神經網路(Artificial neural network)及深度學習(Deep Learning)的快速發展,尤其是深度學習網路對影像的特徵抽取(Feature extraction)和內容的理解能力,似乎讓電腦進行藝術創作出現一絲曙光。
本文將介紹如何在python的Keras深度學習套件中,使用預先訓練(Pre-trained)的深度學習的類神經網路來將一張圖片的風格套用在另一張圖片的內容上。
影像相關的深度學習網路架構
深度學習的類神經網路架構中,最常被使用在影像相關的網路架構就是卷積類神經網路(Convolutional Neural Network, CNN)了。卷積類神經網路中最核心的部份就是卷積層(convolutional layer),一個卷積層通常會由數十到數百個n x n的濾鏡(filter)組成,每個濾鏡會在訓練過程中進行調整,才能夠對不同的影像模式(Image pattern)進行強化。訓練完成後,各個濾鏡就能辨識不同的影像模式。而池化層(Pooling layer)是類似訊號處理中的降維採樣(Down sampling),當數個卷積層和池化層疊加在一起,就能把影像中基本的片段(Patch)組合成物體的結構,並進一步轉化成影像的特徵(Feature)。
然而,要建構出適合的深度學習網路架構,其實要經過許多嘗試和一步步摸索,才能找出最好的網路架構,再加上每次嘗試所要花費的計算資源和時間,通常不是一般的研究人員能夠負擔的。幸好有許多最頂尖的深度學習研究成果都有公開網路架構,方便其他研究人員直接使用或參考。
常見的影像辨識的深度學習網路架構包括,Google提出的GooLeNet (又名InceptionV1)、InceptionV3、和Xception,或牛津大學視覺幾何研究群(Visual Geometry Group, VGG)提出的VGG16、VGG19,或微軟提出的ResNet等等,都是十分常見而且效果很好的深度學習網路架構。通常我們會直接參考或使用各個網路架構。
以牛津大學視覺幾何研究群提出的VGG16深度學習網路架構為例。VGG16的輸入格式是224x224的RGB影像,共有16層網路架構,包括了13層3x3的卷積層來抽取特徵,和3層全連通(Fully-connected)的網路層。另外還有5層的池化層分散在卷積層之間,將網路架構切割成6個區塊,前面5個區塊是由卷積層和池化層組成,用來抽取影像特徵,最後一個區塊是由全連通網路層組成,用來產生ImageNet的1000類影像辨識的結果。
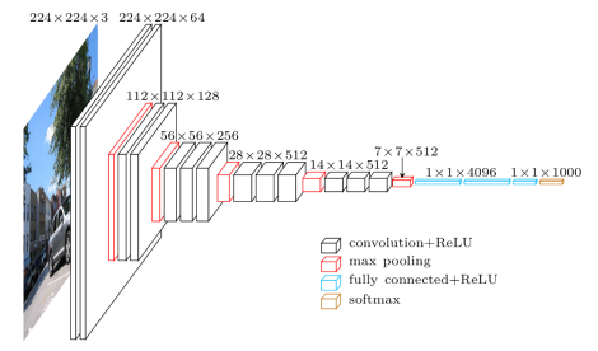
圖一:VGG16網路架構圖
(From: https://www.cs.toronto.edu/~frossard/post/vgg16/)
不止網路架構的細節有在學術論文中揭露,各個深度學習的套件也都提供了建構各個網路架構的程式碼,甚至還有預先訓練好的網路模型(Model)可以直接利用,省去相當多收集訓練資料(Training data)和訓練模型(Model training)的時間。在接下來的部份將會說明怎麼在Keras套件中建構和使用這些深度學習網路架構。
Keras套件與深度學習網路架構
在Keras的Applications套件中,有提供常見的影像辨識深度學習網路架構,包括了Xception、VGG16、VGG19、ResNet50、InceptionV3等等。只要匯入(import)各深度學習網路架構相應的函式庫,就可以使用該網路架構的建置子(Constructor)來產生深度學習網路。而且還能夠自動從網際網路上下載預先訓練好的模型,直接用來進行預測和抽取特徵。
在圖二的例子中可以看到怎麼匯入VGG16的函式庫、及利用VGG16的建構子產生VGG16網路架構,並使用預先訓練好的模型來進行影像辨識。VGG16的建構子常用的參數包括include_top和weights。include_top如果設定成True,在建構網路時就會包括第六個用來產生1000類影像辨識結果的全連通層的區塊;如果include_top設定為False,就只會有前五個用來抽取特徵的卷積層和池化層區塊,所以深度學習網路的輸出會是抽取出來的特徵向量(Feature vector)。weights如果設定成None,就會隨機初始化網路;如果設定成imagenet就會自動下載使用ImageNet資料訓練好的模型,下載的模型檔案會放在家目錄中.keras/models的資料夾。
另外需要注意的地方是keras的Applications套件預設是載入TensorFlow的模型並使用channel_last的輸入順序。如果keras是與theano後端搭配,就需要改動一下Applications套件下載的預訓練模型才能正常運作。
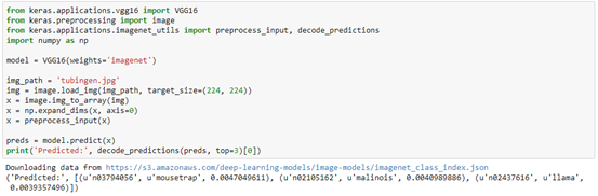
圖二:使用Keras的VGG16網路進行影像辨識
風格與內容的重建與合成
要將一張圖片的風格套用在另一張圖片的內容上,就要從深度學習網路中抽取可以表達內容和風格的特徵,來進行內容重建(content reconstruction)及風格重建(style reconstruction),並利用設計好的損失函數(loss function)和最佳化演算法(Optimization algorithm)來找到最好的圖片輸出。在2015年發表的論文A Neural Algorithm of Artistic Style中,作者Gatys等人提出從VGG網路架構的前五個卷積層和池化層區塊中抽取的特徵,來重建內容和風格的方式;論文中也說明了要怎麼設計內容及風格的損失函數來讓最佳化函式尋找出最好的圖片輸出。

圖三:風格和內容重建的示意圖
(From: A Neural Algorithm of Artistic Style)
在圖四中可以看到內容損失函數content_loss()及風格損失函數style_loss()的宣告和程式碼,而total_variation_loss()是用來降低雜訊的損失函數;圖五中可以看到從VGG網路中抽取特徵及加總不同損失函數的程式碼;圖六中可以看到給定損失函數之後,透過scipy套件提供的fmin_l_bfgs_b()函式尋找出最佳的圖片輸出,下方是每次產生圖片所花的時間和輸出檔案名稱。scipy套件的fmin_l_bfgs_b()函式是在有限的記憶體下的Broyden–Fletcher–Goldfarb–Shanno演算法的實作,在這個例子中的每一個回合都會呼叫這個函式來尋找最佳的圖片輸出。完整程式碼請見:
https://gist.github.com/choupi/05cac0a1b9dd44d5fda91f45755b8e09
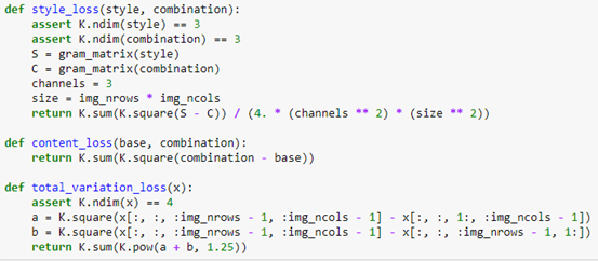
圖四:風格損失函數及內容損失函數

圖五:將不同損失函數加總

圖六:以scipy的fmin_l_bfgs_b()函式尋找最佳合成圖片
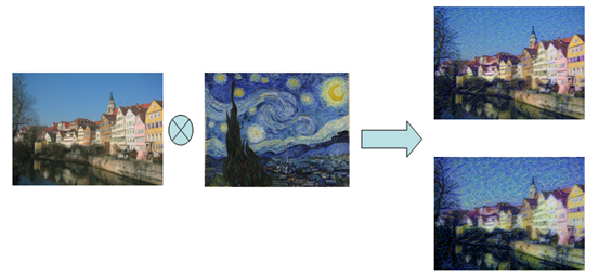
圖七:內容圖片、風格圖片、及合成圖片
結語
深度學習在各種不同應用上強大的效能令人驚嘆,在卷積類神經網路的幫助下不但使電腦可以對影像中的風格和內容有更完整的理解,也能產生出更細膩的視覺作品,讓生成藝術越來越完美,也越來越像人類的畫作了。