深度學習與對抗式機器學習—偷取模型
作者:周秉誼
/ 趨勢科技技術經理
隨著各式各樣的深度學習應用不知不覺遍佈人們的日常生活,與個人隱私或生命財產搭上關係,所以必須正視深習學習系統可能隱含的資訊安全議題。未妥善使用和建置深度學習模型所帶來的問題,可以被有系統的攻擊,這樣的攻擊手法和研究領域就是對抗式機器學習。除了較為人知的Evasion攻擊之外,偷取模型也是會需要小心的。本文將針對偷取模型的手法進行介紹。
前言
隨著深度學習應用越來越普及,我們也就更不能輕忽,深度學習系統也是一個資訊系統,也必須正視深度學習系統隱含的資訊安全議題:研究人員和攻擊者針點深度學習的弱點的系統攻擊。未妥善使用和建置深度學習模型會帶來各項資訊安全問題,這樣的攻擊手法和研究領域就稱為對抗式機器學習(Adversarial Machine Learning)。在對抗式機器學習的各種手法中,除了較為人知的Evasion攻擊可以騙過深度學習模型之外,偷取模型也是需要特別小心的。在本文中將對偷取模型進行介紹。
對抗式機器學習分類
常見的對抗式機器學習,依攻擊手法和攻擊對象的不同,可分為三大類,Evasion攻擊、偷取模型(Model Stealing)、和資料汙染(Poisoning)。分別針對不同的深度學習階段,Evasion攻擊和偷取模型主要針對深度學習上線後使用的過程進行攻擊,而資料汙染是針對訓練資料(Training data)進行攻擊。本文將針對偷取模型的手法進行介紹。
偷取模型的危害
一個可以上線提供服務的深度學習模型,大多是經由大量的資料、大量的研究人員、大量的計算資源、和大量的時間才能開發、訓綀出來的,在這個過程中必然耗費了許多成本,因此深度學習模型不只是一個模型,更是對公司、學術單位來說,十分重要而寶貴的資產。一旦被競爭對手竊取,想必會造成很大的經濟損失。除此之外,攻擊者只要拿到完整的深度學習模型,就可以用白箱攻擊的方式,來對該模型進行非常有效率的Evasion攻擊;還有機會從偷取來的深度學習模型中將原本的訓練資料還原出來,對資料的隱私產生風險。
深度學習應用的型式
深度學習應用通常有兩種方式讓使用者來使用,一種是直接把深度學習模型佈署在使用者端(Client side),不用透過網路就能讓使用者存取深度學習模型;另一種是將深度學習模型包裝為網路服務(Web Service)的型式,讓使用者由網路進行連線,將資料或抽取好的特徵值(Feature)上傳,再由後端伺服器(Backend server)對上傳的資料進行預測(Prediction),再把預測結果回傳給使用者。
第一種方式等於是將深度學習模型的完整內容放在攻擊者可以輕易存取的本地端(Local),所以對有心偷取模型的攻擊者來說,只要使用檔案複製搬移,非常容易就可以取得完整的深度學習模型。因此大部份深度學習應用會將模型加密、或使用封閉的格式等,六增加對模型的保護。然而透過記憶體傾倒(Memory dump)、逆向工程(Reverse engineering)、或是除錯模式(Debug model)、Sandbox環境等手法,還是有很高的機會取得完整的深度學習模型,因此模型還是曝露在極高的風險中。
第二種方式是將深度學習模型包裝在網路服務之後,使用者只能透過API的方式使用深度學習應用,會比第一種方式安全許多,至少沒辦法輕易把深度學習模型檔案複製搬移。然而透過API就真的沒辦法偷取到模型了嗎?
圖1. 透過API偷取模型
偷取線上模型的可行性
先拿一個最簡單的深度學習模型為例,深度學習中的類神經網路其實是由很類似邏輯迴歸(Logistic regression)的神經元(Neuron)所組成的多層網路結構。因此一個最簡單的深度學習模型就是由一個邏輯迴歸的神經元組成的。而邏輯迴歸就是一個線性模型,將多維的輸入資料和權重(weight)做內積加上偏誤(Bias),經過邏輯函數(logistic function)轉換成0到1之間的實數。所以只要知道輸入資料的維度,就可以推算出模型中有幾個變數,再產生一些測試資料透過API呼叫線上的模型,就可以得到一個線性方程組,接下來只要解方程式就可以得到線上模型的權重等參數了。由這個簡化後的例子可以知道透過API呼叫來偷取模型並不是像印象中的這麼困難。
利用可轉移性偷取模型
如果深度學習模型變得更大更為複雜的時候,要猜測出模型的架構就更加不易、也沒辦法只用少量的API呼叫得到線性方程組來反推線上的模型,但並不是這樣線上模型就高枕無憂了。對抗式機器學習的先趨Ian Goodfellow在2017年發表了一篇論文中提到了,應用在同一個問題上的不同深度學習模型之間,有一種Evasion攻擊的可轉移性(Transferability),對於一個深度學習模型的Evasion攻擊也會對另一個深度學習模型有效。因此利用這個性質就能在不知道深度學習模型細節的情況下,也可以一口氣達到偷取線上模型、和Evasion攻擊的目的。

圖2. Evasion攻擊可轉移性
這樣利用可轉移性的攻擊是訓練一個本地的替代模型(Substitute model),用來模擬線上的深度學習模型,而線上的模型就扮演了像一個專家(Oracle)的角色,可以提供本地替代模型有效的答案(Data labelling)。所以整個架構會用線上模型提供的答案來訓練本地模型,就像線上專家模型(Oracle model)在教導本地替代模型一樣。但如果只是單純的收集大量資料來詢問專家模型,其實訓練的效果不會太好、效率也很低下,可能需要跟專家模型的訓練同樣大量的資料才能得到類似的效能。
這個攻擊方式更是聰明的利用了和白箱Evasion攻擊中FGSM相似的手法 。因為深度學習的可轉移性,只要依照替代模型的梯度(Gradient)方向,對資料進行修改,就可以製作(Crafting)出特殊的資料。以這種方式產生出來的資料,對專家模型來說,都是十分關鍵,可以有效評估(Evaluate)專家模型的敏感性(Sensitivity)。這些產生出來的資料可以想成是分佈在專家模型的決策邊界(decision boundary)附近,所以是一群最重要的訓練資料。而使用這樣的資料來進行訓練,就可以用非常少量的查詢(Query),就能得到最大的效益。
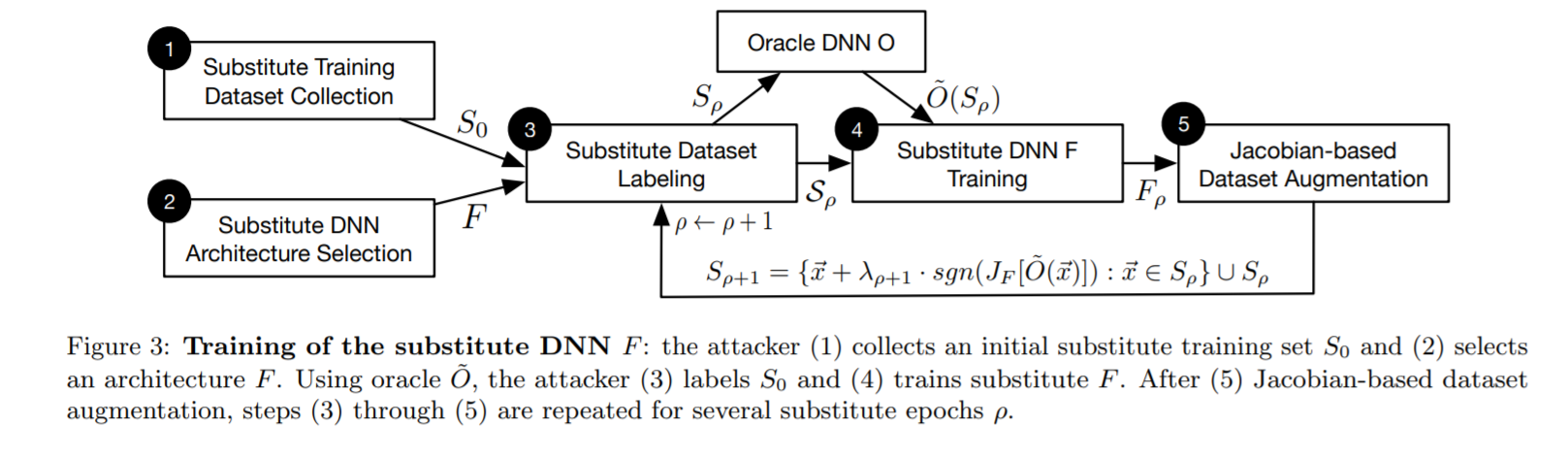
圖3. Evasion和偷取模型同時進行的攻擊流程
(Source: Ian Goodfellow, Practical Black-Box Attacks against Machine Learning, 2017)
實際上的攻擊進行中,會先用少量收集來的資料,詢問專家模型得到答案後,先訓練出初版的替代模型,再利用替代模型的梯度來進行資料調整(argumentation)。得到調整後的資料,再拿去詢問專家模型得到新的答案,有了新的資料和答案又可以用來更新本地的替代模型。如此不斷重復,就可以用相當少量的資料,複製線上的專家模型。這個攻擊手法巧妙的結合了偷取模型和Evasion攻擊的手法,也可以在黑箱攻擊的情境之下,以白箱攻擊的技術對線上模型進行有效率的攻擊。
在Ian Goodfellow的論文中,也評估了這個攻擊手法對於傳統、非深度學習的機器學習模型,和Amazon、Google的線上機器學習平台的攻擊效果。對於深度學習模型、線性模型、SVM、kNN等機器學習模型,都有很好的偷取效果,只有對於決策樹(Decision tree)類的機器學習模型的偷取效果比較差。
結語
一個可以上線的深度學習模型背後代表了企業、學術單位內部大量資料、大量研發、大量計算資源、和大量時間等難以估計的成本,模型更是重要的資產,一旦被竊取,不只是經濟上、更有信譽上的損失,整體損失是難以估計的。因此如何保護好深度學習模型,也是在開發深度學習應用時,需要投注更多心力的大議題。線上模型的應用方式比起部署在客戶端,可以讓模型更為安全,但也不能太過掉以輕心。因為Evasion攻擊可轉移性可以有效增進偷取線上模型的效率,讓大家印象中難以偷取的線上模型,成為攻擊者眼中的目標。