首頁 >技術論壇
深度學習與對抗式機器學習—Evasion攻擊
隨著各式各樣的深度學習應用不知不覺遍佈人們的日常生活,與個人隱私或生命財產搭上關係,所以必須正視深度習學習系統可能隱含的資訊安全議題。未妥善使用和建置深度學習模型所帶來的問題,可以被有系統的攻擊,這樣的攻擊手法和研究領域就是對抗式機器學習。本文將針對其中的Evasion攻擊進行介紹。
前言
隨著各式各樣的深度學習應用不知不覺遍佈人們的日常生活,也有越來越多重要的個人資訊、或門禁等安全系統,也開始使用深度學習來協助人們處理各式各樣的資訊。然而一旦與個人隱私或生命財產搭上關係,就由不得我們輕忽,深度學習系統也是一個資訊系統,我們也必須正視深習學習系統可能隱含的資訊安全議題。研究人員和攻擊者都已開始注意深度學習特別的弱點,進行有系統的攻擊。在本文中將針對未妥善使用和建置深度學習模型所帶來的問題進行介紹,這樣的攻擊手法和研究領域就是對抗式機器學習(Adversarial Machine Learning)。
對抗式機器學習分類
常見的對抗式機器學習,依攻擊手法和攻擊對象的不同,可分為三大類: Evasion攻擊、偷取模型(Model Stealing)和資料汙染(Poisoning)。Evasion攻擊和偷取模型主要針對深度學習上線後使用的過程進行攻擊,而資料汙染是針對訓練資料(Training data)進行攻擊。本文將針對Evasion攻擊進行介紹。
Evasion攻擊
Evasion攻擊是最常見也最容易應用的攻擊。深度學習也和傳統機器學習一樣,會讀入一些輸入資料(Input data),經由深度學習模型和資料間的計算,得出對此筆資料的預測機率值(Probability)或分類(Classification)資訊。而Evasion攻擊就是希望對輸入資料進行非常細微的修改,大幅改變深度學習模型的預測結果。Evasion攻擊可以分為兩大類,黑箱攻擊(Black box attack)和白箱攻擊(White box attack)。

圖1. Evasion攻擊
黑箱攻擊是把深度學習模型當成黑盒子,在未取得深度學習模型細節的情況下,對該模型進行攻擊,大多是以隨機變異(Randomized permutation)的方式進行攻擊。以圖片資料做為例,即是在圖片資料中加入隨機的雜訊(White noise),來增加深度學習模型誤判的機率。然而對於大部份卷積神經網路(Convolutional neural network, CNN)來說,只是隨機加入的雜訊並不能有效的影響模型預測的結果,進而改變預測結果。但如果在攻擊過程中,能取得深度學習模型對修改後的輸入資料的分類機率的改變,就可以用更有效率的方式進行攻擊。
在能夠取得預測值的情況下,攻擊者可以先由輸入的圖片資料產生出許多有非常小變異的圖片,把這些圖片交由深度學習計算得到每張圖片的預測值,從中選取出預測值改變量最大的一張,成為新的原始圖片,接著持續重複上面的步驟,經由數個迭代後,就能找到足以讓深度學習模型誤判的修改後的圖片了。更進一步,甚至可以使用基因演算法(Genetic Algorithm)等演化式計算(Evolution Computing),讓隨機變異的過程更有效率、更容易產生出黑箱攻擊的圖片。
白箱攻擊則是在取得深度學習模型細節的情況下,包括模型的網路架構、各個神經元的每一個參數(Weight)時,可以進行的更有效率的攻擊。在取得模型細節之後,攻擊可以使用神經元的參數和輸入資料進行計算,得到該輸入資料的每一個資料點對該模型的梯度(Gradient)。進一步利用梯度的正負值,對原始輸入資料的每一個資料點進行小小的異動。以圖片來說,就是對每一個像素(Pixel)依其梯度的正負值加上或減去一點點的變動,就可以產生出足以大幅改變該深度學習模型預測結果的輸入圖片。
上述的白箱攻擊即是FGSM (Fast Gradient Signed Method),是由Ian Goodfellow與其他Google研究人員在2014年發表的。FGSM巧妙地利用了深度學習模型和輸入資料的梯度方向,就能以十分細微的變化,大幅改變模型預測結果。圖3.是以FGSM對Logistic Regression進行攻擊的一個例子,可以讓我們更加理解FGSM的精華。圖中表格第一行的X代表原始的輸入資料,第二行的W代表Logistic Regression模型中的參數,第三行則是以FGSM修改後的輸入資料。在下方的算式可以看到原本模型的預測結果是0.0474,約為機率值5%。但FGSM對每個資料欄位以梯度方向小小修改後的資料,經過模型計算可以得到88%的機率值,等於是將預測結果完全反轉了。由此也可以知道FGSM是如此的簡單和有效。因此由FGSM也產生了不少的變型,如One-step Target Class Method可以指定資料改變的方向性、Iterative FGSM以多次的FGSM讓預測結果改變幅度更大。圖4.中是實際以One-step Target Class Method進行攻擊,對圖片以極小的變異修改,最左邊是原本的圖片,深度學習模型認為有99.6%的機率是大貓熊,最右邊是以One-step Target Class Method對原本圖片修改後的圖片,中間的圖片就是兩張圖片的差異放大了100倍後的結果。修改後的圖片和原本圖片以肉眼幾乎無法看出差別,但對深度學習模型的預測結果卻是巨大的影響。
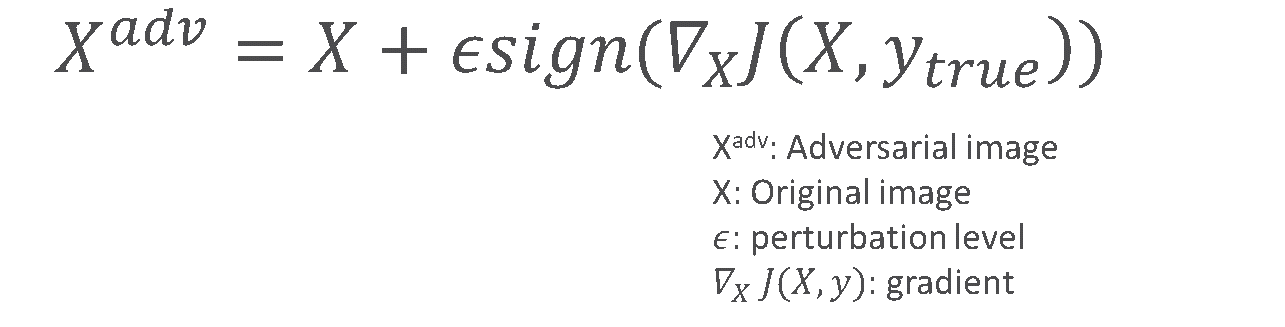
圖2. Fast Gradient Signed Method

圖3. FGSM對Logistic Regression進行攻擊
(Source: Fei-Fei Li, Andrej Karpathy, Justin Johnson, Lecture 9-72, 2016)
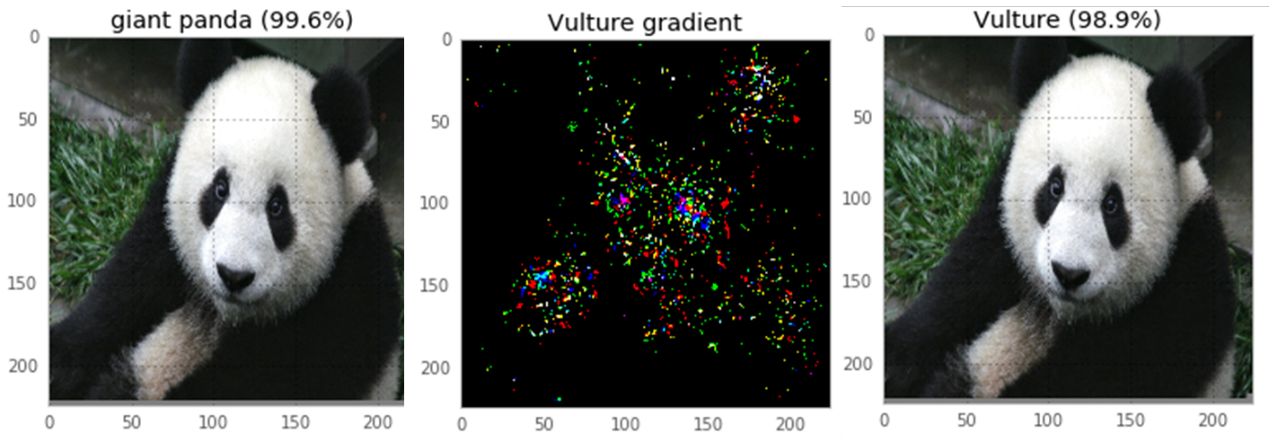
圖4. One-step Target Class Methods攻擊前後圖片與放大100倍之變異
由上面對Evasion攻擊的描述可以知道白箱攻擊的效率和效果比黑箱攻擊更好,所需的計算資源和計算時間也比較少,如果身為攻擊者當然會想要使用更有效率的白箱攻擊。而要能夠進行白箱攻擊的關鍵就是能否取得深度學習模型,所以模型本身的安全程度和模型資訊的曝露程度也影響了模型被攻擊的可能性。
NIPS 2017對抗式機器學習攻防競賽
為了找出對於對抗式機器學習中Evasion攻擊的最佳攻擊手法和防禦策略,在2017年Google也和最為知名的深度學習研討會NIPS 2017合作,在Kaggle平台上舉辦了對抗式機器學習攻防競賽(Competition on Adversarial Attacks and Defenses)。競賽的主題是影像辨識(Image Classification),圖片的類別採用ImageNet的1000個類別,而競賽內容分為三個部份,無指定目標的Evasion攻擊(Non-targeted Adversarial Attack)、指定目標的Evasion攻擊(Targeted Adversarial Attack)、和Evasion防禦(Defense Against Adversarial Attack)。針對各個項目,參與者需要準備一個Docker環境,在限定時間內對大量的輸入圖片進行修改,每張圖片的修改程度會被限制在某個差異值以下,卻讓修改後的圖片可以有效騙過其他參與者準備的Evasion防禦模型。在無指定目標的Evasion攻擊項目中,參與者的Docker環境要讓修改後的圖片越不像原本的類別,得到的分數越高。在指定目標的Evasion攻擊中,修改後的圖片要越像指定的目標類別,得到的分數越高。在Evasion防禦中,參與者一樣是上傳一個Docker環境來對修改前和經由攻擊組修改後的圖片進行辨識,能夠正確識別越多圖片,則分數越高。
經過實際比賽攻防兩方的較勁,最佳的攻擊者在無指定目標的Evasion攻擊上可以達到近八成的成功率,而指定目標的Evasion攻擊也可以達到四成的成功率,也代表著如果沒有針對Evasion攻擊進行防禦,深度學習模型的確會面臨十分有效的Evasion攻擊。而最佳的Evasion防禦者可以得到九成以上的分數,也代表有系統的防禦和打造深度學習模型,是可以有效防禦Evasion攻擊的。
Evasion攻擊的防禦對策
常見的防禦策略包括Ensemble及Stacking、以Evasion手法產生訓練資料、及去除雜訊(Denoise)。
通常以白箱攻擊方式進行Evasion攻擊,需要針對特定的深度學習模型,並依輸入資料不同產生出對應的梯度來修改輸入資料。然而使用多個不同網路架構的模型,或再搭配其他非深度學習的機器學習模型,就會讓攻擊者不易對單一模型產生梯度,進而增加攻擊的復雜度和成功的難度。如直接將VGG模型和Xception模型的預測結果整合後,產生最終預測值。這樣的方法和機器學習常見的Ensemble和Stacking相似,也是有效提高整體預測穩定性的好方法。
在深度學習模型訓練完成後,也可以自行產生一些Evasion攻擊的資料,再把這些資料加回訓練資料中,對先前的模型增加數個訓練迭代,也可以有效增進模型對Evasion攻擊的抵抗能力。這樣的手法跟影像處理和傳統機器學習中常見的Distortion手法也有異曲同工之處。
通常自然界中的影像都是平滑的,不會有非自然的雜訊,因此雜訊可能是由相機取樣時產生、或人為刻意加入的,如前述提到的Evasion攻擊產生的雜訊。所以如果在將資料輸入到模型前,先以某些影像處理或用深度學習模型來移除雜訊、或對影像平滑化,就可以消除Evasion攻擊刻意加在圖片中的雜訊,進而增強對Evasion攻擊的抵抗能力。
結語
對抗式機器學習中的Evasion攻擊是對深度學習模型相當有效而往往被人們所疏忽的。雖然在一般的影像辨識的應用中,可能造成的傷害並不會太大,但隨著深度學習被使用在越來越多個人隱私或生命財產安全的應用,未能注意到相關問題所隱藏的資安風險,也會越來越高。不過如果在深度學習的訓練過程中,留意一些小細節,也是可以有效防禦Evasion攻擊的。