首頁 >技術論壇
使用GPT2-Chinese生成中文小說
自然語言生成(Natural Language Generation,NLG)是自然語言處理(Natural Language Processing,NLP)重要的一環,它漸漸打破了人機之間資訊交流的藩籬,試著將大量非結構性資料,轉變成人類能夠理解的格式。近年神經網路架構Transformer的討論度不斷提高,以Transformer為基礎,用來進行文字生成的GPT家族,也應用在各種領域。在本文中,將介紹如何整合GPT2-Chinese工具,進行語料訓練與生成等過程,分享給需要進行中文生成的相關工作者。
前言
GPT是由人工智慧研究組織OpenAI於2018年6月所提出的一種文字生成預訓練語言模型(Pre-trained language model),使用了5GB的資料量進行訓練;在2019年2月,推出了GPT-2,使用了40GB資料量進行訓練,僅透過一段簡單的前導文字(prefix),便可生成幾可亂真的內容,產生了前後文具有高度連貫性(coherence)的文本,麻省理工科技評論(MIT technology review)也曾嘗試用其進行新聞生成,獲得了相關產業的高度關注;2020年5月,GPT-3橫空出世,使用45TB資料量進行訓練,不僅可以生成內容和主題高度相符的文章段落,還能將數學公式作為前導文字,在生成後輸出正確的結果,或是描述一段程式功能開發需求,立即產生對應的程式碼。GPT2-Chinese是一個GitHub上的開放原始碼工具,使用Python程式語言開發,可以用來訓練中文語料,其生成文字的風格,取決於訓練語料的格式。
訓練方式
建置Python執行環境後,到GitHub搜尋「GPT2-Chinese」,會看到作者Morizeyao的專案,切換到舊分支(old_gpt_2_chinese),在專案中按照requirements.txt進行套件安裝,建議使用已配置高階GPU的環境,訓練時間將明顯縮短。檔案train.json是訓練格式的範例,類似一維陣列,只要將中文語料依序帶入,便能開始進行訓練。
訓練語料格式 |
["第一篇文章的正文", "第二篇文章的正文", "第三篇文章的正文"] |
表1 訓練語料的格式,簡單易懂
將訓練文字各別帶入train.json後,便能開始訓練。以Linux環境為例,其訓練指令與生成指令,如表2和表3所示,其訓練指令說明與生成指令說明,如表4和表5所示:
訓練語料的指令 |
python train.py \ |
表2 訓練指令
生成文字的指令 |
python generate.py \ |
表3 生成指令
參數 |
說明 |
train.py |
訓練用的主程式 |
device |
指定用哪一個 GPU,0代表第1顆 |
epochs |
訓練幾回 |
batch_size |
每次拿幾個樣本進行訓練 |
min_length |
每個樣本至少需要多少長度才會拿來訓練 |
raw_data_path |
訓練資料 JSON 檔案路徑 |
output_dir |
訓練完的語言模型存放資料夾 |
raw |
設定此參數,會將樣本進行 tokenize |
表4 訓練的指令說明
參數 |
說明 |
generate.py |
生成文字用的主程式 |
length |
生成文字的長度 |
nsamples |
生成幾個文章範本 |
prefix |
生成文章的前導文字,會影響生成的發展 |
temperature |
生成溫度越高,語言模型生成出來的結果越隨機;換言之,原先容易被選到的字,抽出的機會變小,平常較少出現的字,被選到的機會稍微增加 |
model_path |
生成文字所使用的語言模型資料夾路徑 |
save_samples |
有設定的話,會儲存生成文章的範本 |
save_samples_path |
生成文章範本的儲存路徑 |
表5 生成的指令說明
圖1是訓練過程中,每個 step 輸出 log 的畫面;圖2是每訓練一回合後,各別儲存語言模型的畫面:
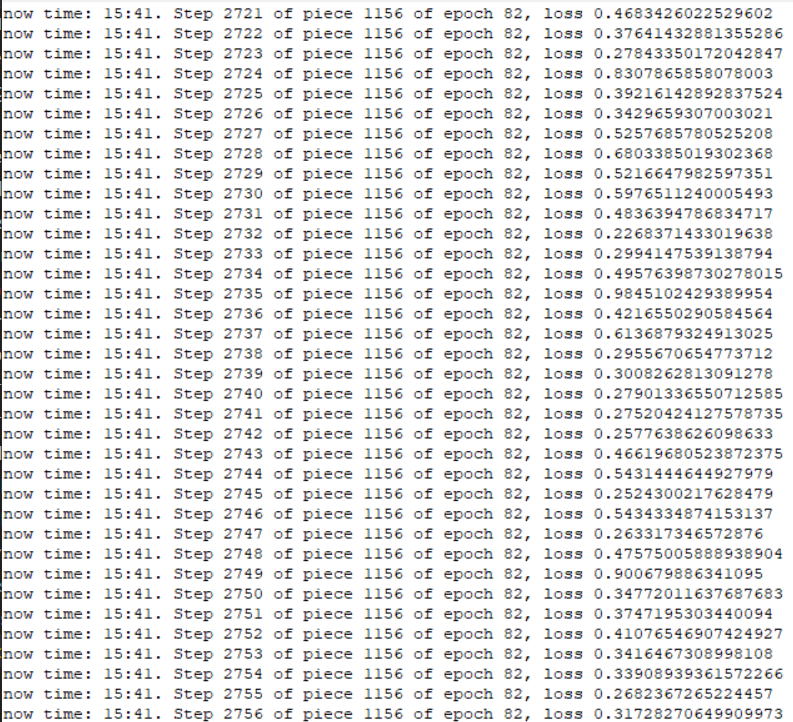
圖1 訓練過程
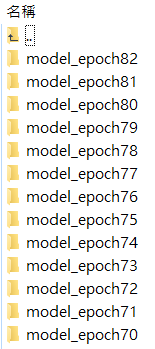
圖2 每訓練完1個epoch,就會各別儲存1次model
取得訓練資料
本文以網站「金庸小說線上閱讀」作為訓練語料的資料來源,其中包括了知名的「飛雪連天射白鹿、笑書神俠倚碧鴛」等知名金庸武俠小說。YouTube上有許多網路爬蟲的教學影片,可以參考「[requests]取得金庸小說的內容,並存成txt與json檔」和「[selenium]取得金庸小說的內容,並存成txt與json檔」兩段影片,影片當中說明如何取得網站上面的所有金庸小說文章,作為訓練來源,值得大家參考。圖3顯示了進入網站首頁的內容:

圖3 金庸小說線上閱讀網站的首頁
生成結果
訓練完成後,可以透過表3的指令,進行小說生成。在生成前,需要準備一段前導文字,作為生成小說的第一段話,這段話決定了文字生成的發展與故事走向,內容愈豐富,描述的人、事、時、地、物愈多,小說生成會愈聚焦在前導文字的內容,以圖4的「張無忌見三名老僧在片刻間連斃崑崙派四位高手,」為例,會發現生成的結果通常都會往前導文字的內容發展,隨著訓練的次數愈多,生成的內容會更完整:
![]()
圖4 生成金庸小說的範例
生成中文小說的原理,如圖5所示,是透過條件機率(Conditional Probability)來進行文字生成,由於每次生成都會回顧過去生成的文字,因此前後文便會具有高度的連貫性:
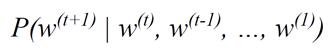
圖5 生成文字的條件機率
延伸應用
GPT2-Chinese不僅可以生成中文小說,只要調整訓練的語料內容,生成結果將以語料的格式進行輸出,以圖6為例,語料格式為連續性的對話,其生成結果將會接近訓練語料的風格,倘若生成的結果尚能接受,將其當作下一次生成的前導文字,便能生成具有高度連貫性的前後對話;又如圖7,將詩詞以兩句作為一組訓練語料進行訓練,生成的結果不但不會重覆,還可能創造出更有意境的新文句。
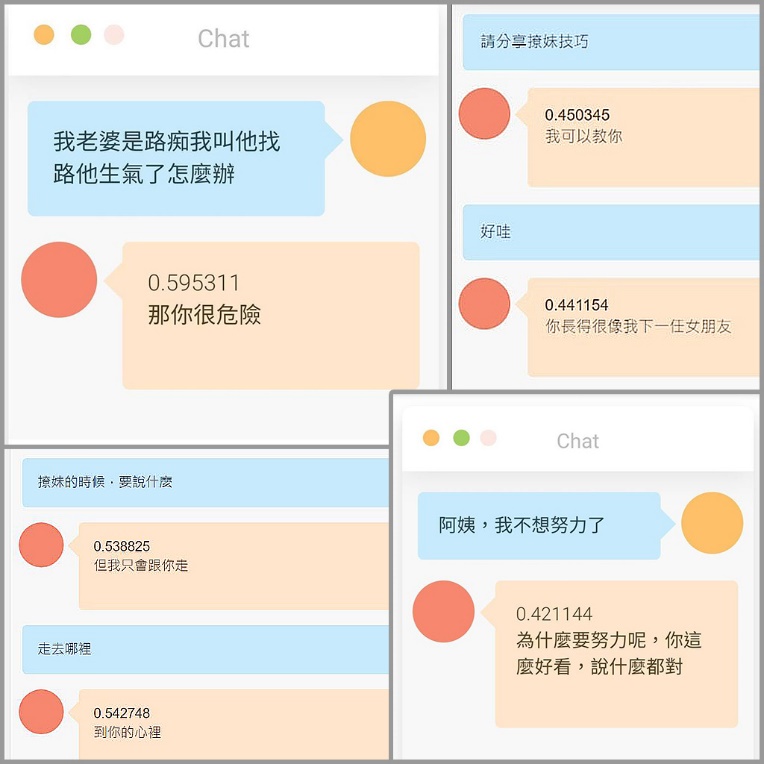
圖6 調整語料進行訓練,可用於單輪、多輪對話

圖7 將調整後的詩詞進行訓練,可生成更有意境的文句
後記
訓練法律判決書的內文,可以生成判決書的格式;嘗試訓練撩妹語料,可以生成趣味橫生的撩妹文句;若是將圖片像素進行序列化,以訓練格式進行儲存,也會生成各式各樣有趣的圖片。GPT2-Chinese的用途很廣,運用之妙,存乎一心。
參考資料
[1] GPT2-Chinese
https://github.com/Morizeyao/GPT2-Chinese
[2] 金庸小說線上閱讀
https://www.bookwormzz.com/zh/
[3] [requests]取得金庸小說的內容,並存成txt與json檔
https://youtu.be/JsmLtMC43Lc
[4] [selenium]取得金庸小說的內容,並存成txt與json檔
https://youtu.be/jJzZcMjZsKM
[5] [GPT2-Chinese old branch] 中文語言模型訓練與生成
https://youtu.be/c3fHRQonqlM
[6] 網路爬蟲教學範例
https://github.com/telunyang/python_web_scraping
[7] 詞向量之GPT-1,GPT-2和GPT-3
https://zhuanlan.zhihu.com/p/350017443
[8] 直觀理解 GPT-2 語言模型並生成金庸武俠小說
https://leemeng.tw/gpt2-language-model-generate-chinese-jing-yong-novels.html