作者:呂佳勳 / 臺灣大學計算機及資訊網路中心程式設計組幹事
Text Mining,中文稱為文字探勘,是一種利用電腦技術判讀文章特徵的技術。簡單的說,我們可以藉由適當的演算法,讓電腦能夠「讀懂」人類寫的文章。本文將會簡單介紹文字探勘在日常生活中的應用,並展示一個實際的案例供讀者參考。
文字探勘已充斥於生活之中
從上世紀中期開始,就有許多科學家為了研究如何讓電腦能夠辨識人類所說的話而做了許多的努力。在語言學家與電腦科學家的合作之下,漸漸發展出了一門稱之為自然語言處理(Natural Language Processing)的學門,所謂的自然語言指的是自然而然發展出來的語言,像是我們平常所說的中文、英文與日文等等。而相較於人工創造出來的程式語言或世界語,自然語言顯示了它的不規則與多變性。比如說,同一個字在不同場合有不同的念法,或有不同的意思。而每天都不斷有新的詞彙被創造出來,這導致了自然語言難以被駕馭的特性(因此才需要靠語言學家與電腦科學家的合作)。
而在進入網路時代後,每天出現在你我周遭的文字量已經到達了看都看不完的爆炸性階段,資訊不斷的湧來,我們只能選擇那些我們最有興趣的東西去看(即使是這樣,還是看不完!)。因此,各大網路公司無不絞盡腦汁去處理好它們提供給我們的產品。以資訊巨頭谷歌(Google)來說,幾乎所有的東西都跟自然語言處理有關,它們的基本搜尋業務,是靠著先把網路上龐大數量的網頁給爬下來,並建立各種索引以後存到資料庫中,你我才能在0.1秒內以關鍵字搜尋到我們想找的東西。谷歌也根據了你我的搜尋關鍵字,配給了相關的廣告到我們面前,從廣告商那邊賺取的錢,已經成為這家網路公司最主要的收益來源。甚至你我使用的Gmail,都不斷的被電腦掃瞄、監控著(而這居然並不違法)。谷歌的自動翻譯也取代了我們以前用的電子翻譯機,甚至強大到任何語言都有,而且還不斷的在進化中。其他像是推特、臉書、Linkedin等公司,只要它們掌握了大量的文字,要做到什麼事都是有可能的,像是從你的文字中判斷出你的情緒、人格、喜好等等,我們每天所發的文章、交談的訊息,都會在經年累月下把你這個人賣給了公司。因此,在網際網路時代,文字探勘已經是一門不可忽視的學問了。
藉由程式語言來實際應用
接下來,筆者會展示一個文字探勘的應用,這部分會使用Python這個程式語言。目前網路上已經有許多的套件和模組可以用來處理文字探勘,只要能夠理解其原理,並稍微了解程式碼,相信大家都能做到簡單的文字探勘。而目前比較常看到的是文章推薦,相信大家在瀏覽網站的時候,旁邊一定都會出現一些,你可能會對這些文章感興趣之類的東西吧!那麼它們是怎麼做到的呢?老練的讀者們可能已經發現網路文章的編輯者都會在文章旁邊標出這篇文章相關的關鍵字,因此系統可以自動推薦相關關鍵字的文章給您看。但是,要是這篇文章沒有人來幫它寫關鍵字呢?沒有人來告訴你這篇文章是有關於什麼的呢?(像是每個人在社群網站上留下的文章,有許許多多雜亂不規則的非結構化文字)這時,就是機器上場的時候了。
我們以台大電子報系統為例,試想如果我們能把電子報的每一篇文章都找出其關鍵字,或是找出每篇文章之間的相關度,這樣不就可以在讀者閱讀某篇文章時,自動推薦相關的文章給他看嗎?這樣既可以滿足讀者的求知慾、也活化了過期電子報的資源利用。

圖一
上圖是筆者將每篇電子報的純文字資料存到資料庫的樣子,有了這個以後,我們就可以開始分析文章了。首先先將每篇文章內容分詞,所謂的分詞指的是把相連的文字給拆成一個一個詞彙。像是「今天天氣真好」,我們就可以把它拆成「今天」、「天氣」、「真好」。接下來就是賦予這篇文章一個特徵,這特徵從何而來?當然就是從剛剛分詞的結果來判斷囉~比如說我們可以把每一個相異的詞當成一個向量,這樣每篇文章就有了屬於它自己的向量組成(特徵)。有了特徵之後,我們就可以計算不同文章之間的相似度,藉由向量的各種正交性,其複雜度或是計算方式隨您高興,藉此得出每一篇文章之間的相關程度。
再經過了一些繁瑣的過程之後,我們將運算結果存入資料庫,其內容就如下圖這個樣子:
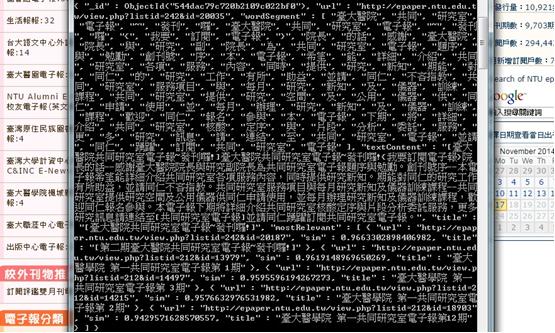
圖二
大家可以看到台大醫院共同研究室電子報的創刊號已經被拆成一個一個的詞彙,並且在最下面的mostRelevant欄位中,顯示了與其最相關的幾篇文章,sim代表相似度,已被筆者正規化為0~1的數值,越接近1代表越相似。以上這個跳躍式的展示,筆者已經省略了許多的細節沒有在這一一詳述。但是其每一步都是值得更深一步探索的,像是如何分詞才能分的好?分出來的詞是有意義的嗎?如何計算相似度?而至此我們只做了文字上的比較,就能找出文章的關鍵字或是主題,那如果更深入分析呢?當然這就延伸出更多的學問了。
文章所透露出的人類語意,才是Text Mining真正的價值,比如說廠商可以根據人們在網路論壇中所評論的文字,而判斷說某個商品賣得好不好,或是某個活動辦的成不成功,雇幾個工讀生慢慢看也可以,當然。但是如果您的範圍擴充到全球的網際網路市場呢?總不可能讓人類慢慢的看了吧?不論在即時性還是數量級來說,藉由設計精良的NLP演算法來驅動商業發展已經是未來的一股趨勢,掌握了文字、就掌握了力量。