作者:許凱平 / 計算機及資訊網路中心作業管理組程式設計師
資料探勘(Data Mining)[1]近來得到不少注目,除了不少年輕學子躍躍欲試,也讓眾多的專家覺得自己的經歷如果沒有加上資料探勘這項專長,好像就跟不上時代。但是如果事先的準備工作沒有做好,貿然進行,不但白花功夫,也會賠上自己的名聲。另外,個資法已經上路了,在處理機敏資料的探勘時,也要格外小心,小則不能發表,大則可能會有法律上的糾紛,不可不慎。
前言
經過大眾傳媒的渲染,資料探勘近來得到相當大的關注。感覺上它好像是一種神奇的魔法,只要施法在資料上,就會找到人類所不能見、無法發掘的事實,甚至強大到可以預測未來。例如在「美國隊長2」[2]電影中,HYDRA組織開發了一個資料探勘演算法,用來從巨量資料中找出潛在的敵人。或是像「疑犯追蹤」[3]劇集中的機器,可以從監聽資訊中以偵測恐怖攻擊,進而預防犯罪。 被資料探勘的神奇力量吸引後,大家一定躍躍欲試,想要一展身手,成為資料探勘的高手。最神奇的是,這種魔法也不用寫程式也不用花錢買,只要下載商用軟體的試用版或上網搜尋免費的工具來用。安裝完成後,彷彿我已經變成資料探勘的魔法師!
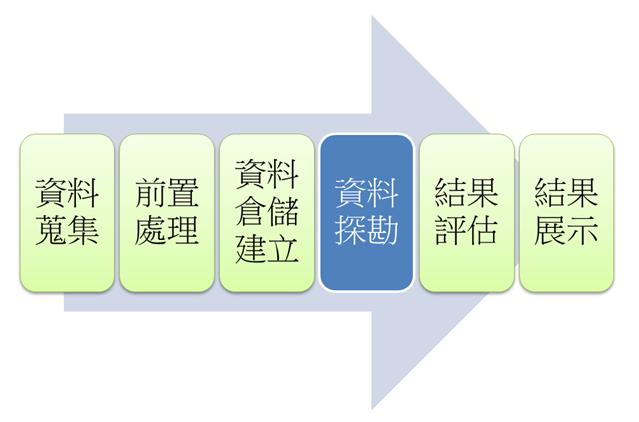
Figure 1 知識發現的基本步驟
現實世界沒有這麼美好,資料探勘只是知識發現的過程的一個重要步驟[4]。但無論是之前的資料蒐集、前置處理與資料倉儲建立,或是之後的結果評估與展示,也都很重要,甚至會有80%的時間與精力是花費在前置處理上。因為如果其中一個步驟沒有做好,接下來的辛勞就是白花時間。依據不對的資料,最後做出的結果就可能有所偏離事實,甚至於做出錯誤的結論。
資料蒐集
網路資料的來源首選當然是網路上公開的資料,再來才是自己蒐集的資料或是跟一些機構申請。舉例來說,政府資料開放平臺上就有不少公開的資料集,另外國衛院也有全民健康保險研究資料庫可供申請。如果寫論文的重點在於演算法的改進,為了比較,最好還是找一個廣為周知的資料集,如威斯康辛大學的乳癌資料集,或是要改進的演算法的相關論文所使用的資料。如果要處理的是尚未數位化的資料,首先要做的就是資料建檔的工作。因為這部分的資訊較為缺乏,筆者就只針對這部分加以說明。
書面資料數位化
為了避免未來的資料分析做白工(垃圾進垃圾出),仔細規劃數位化建檔的工作流程是非常重要的。第一次做大量資料建檔工作的人,常常會想到可以利用掃描器與字元辨識軟體利用電腦自動將書面資料數位化。但是在我的經驗中,這個做法對於書面資料常見的手寫文字與表格資料的辨識率實在是慘不忍睹。況且就算是正確率達99.9%,在進行資料確認的時候,還是要由人眼從1000個字找出那弄錯的一個字,這也不是一件容易的事。
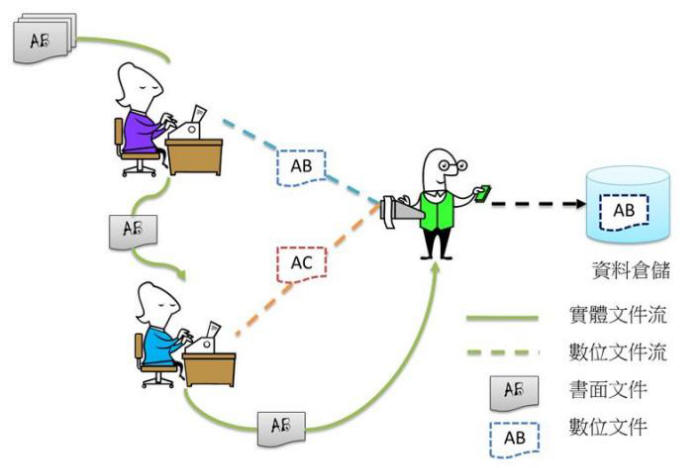
Figure 2 大考中心雙線輸入比對的數位化流程
我們可以參考大考中心非選擇題的分數登錄的做法:將同一筆書面資料由兩個人分別輸入,然後再由第三人以電腦進行比對;如果不同,再取出原始資料進行補登,以減少打錯字的可能性(除非這兩位打字人員打錯同一個字,並且錯的一樣,例如都把13看成15)。這樣的作法,進度通常不會太快;如果要增進效率,可以參考台大植物標本館的做法,先將每一張書面資料預先掃描。這樣的做法不用等書面資料,可以同時有大量人員登打,也可減少遺失的可能性。此外,在做資料確認的時候也不用去成堆的書面資料找原始檔案,可以直接調出圖檔進行判斷,作業的品質(誰老是打錯)與進度容易掌握與控制。總和來講,如果可以設計專用的輸入軟體,在資料輸入時做檢查,就可以大幅增進資料的品質,增進工作人員的效率,配備雙螢幕也是個不錯的做法。對於重要資訊(例如陰性/陽性),以人工清點筆數,再跟數位化結果比對也是個檢查人工輸入正確性的好方法。
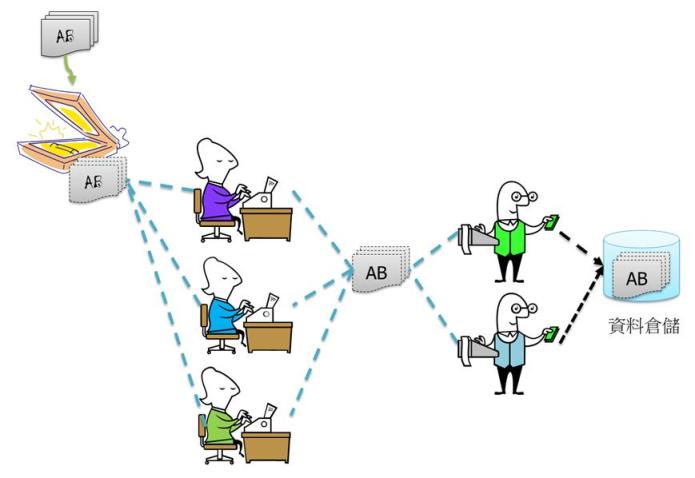
Figure 3 預先掃描的數位化流程
有了這些手段,可以將錯誤的機率降到很低,但只要資料量夠大,還是會有同時輸入錯誤的發生。舉例來說,我所參與過的一項以新生兒篩檢資料做罕見疾病判讀的研究中,就碰到換演算法,調整各種參數卻始終無法將個案分類的情形。最後以除了序號外的所有檢測資料進行分組,終於發現是因為數位化後的檢驗結果中有兩筆各項檢出數字都是相同,但是卻分別為陰性與陽性的情形。照理各項檢出都一樣,應該判讀出一樣的結果才對,翻出原始書面資料才發現醫檢師並未判讀錯誤,而是兩個資料在數位化過程中同時輸錯的情形。所以在進行探勘前,有效的前置處理是一件非常重要的事情,及早洗乾淨是第一準則。
前置處理
無論是網路下載、自行建檔或是要來的資料,都必須先假設資料是有問題的,然後再一步一步證明它是正確性,然後將有問題的資料逐筆以合理的更正、刪除或補齊。除了每個欄位的是字元或數字的判斷外,各個欄位也可以利用既有的知識加以檢查,例如身高、體重與血壓都有一定的合理範圍。
每一筆資料都要有唯一序號,另外如果有欄位使用代碼的話,所有資料的代碼都必須是存在於代碼表。有些代碼表會逐年編修,也就是說,同一個意義可能會有不同的代碼,或是同一個代碼每年的意義不同。碰到這種情形,如果要做跨年的統計,就要先將代碼對齊到某一年份,否則做出來的也沒有意義。例如選課系統的課號每年都會重編,每個課號所對應的課程每年都不同,我們在統計歷年最受歡迎的課程的時候,以課號做跨年加總便會沒有意義。
個人識別欄位處理
為了保障個人隱私,資料中的識別資料通常會被移除、遮蓋或是取代[7]。除了移除外,另外部分遮蓋的方式也常見,例如將電話號碼標示為09889*5*6*,身分證統一編號顯示為A12345****等等。如果要對個案的追蹤分析的話,我們就必須能分辨出這兩筆資料是否屬於同一個人的(串檔),因此移除或遮蓋就這個情形來說並不適合。這種情形可使用雜湊或加密函數進行識別值的取代;例如用MD5[5]將身分證號碼轉成雜湊值6383cdd475948f5f2ac4de348932c6e8回填。這個方式看似沒有問題,似乎上難以從6383cdd475948f5f2ac4de348932c6e8推回原來的身分證號,然後又可以保持唯一性(衝到的機率很小,可以事先檢查)。
但必須注意到因為身分證號碼有其編碼規則,所有合法身分證號碼的數量也有限,如果有人先將所有身分證號碼的雜湊值算出,建立(身分證號碼,雜湊值)的對應表,就可以反過來從雜湊值找到身分證號碼。所以如果資料提供單位在送出研究資料的時候,直接將身分證號碼取雜湊值的話,取得資料的人如果有心,不難將身分證欄位還原。還好大部分的資料提供單位意識到這個弱點,在進行雜湊前,會先將身分證號碼附加長字串(salt),讓有心人士難以建表反查。
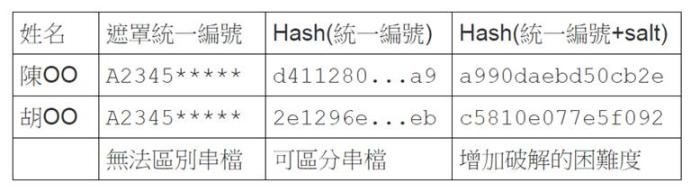
Figure 4 身分證統一編號的處理
回到校園,如果是學校單位要提供資料給合法申請的研究單位進行研究時,也要記得不能直接將學號做雜湊,一定先將學號附加一個亂數產生的長字串,以減少遭到破解的可能性。國衛院[6]的一個值得參考的做法,對每一個申請資料單位搭配一個特有的附加字串:一方面可以讓申請單位可以串起同一個人的資料,另外萬一外流,也可以追查出是哪個申請單位外流的(如果識別欄位還在的話)。當然這個搭配字串也需妥善保管,不能讓外界及申請單位知道。再怎麼嚴密的做法,如果碰到無限,最終被破解的可能性還是很大,所以一定要慎重。
結論
就算是事情準備得再周全,做出多好的結果,能夠說服領域專家的案例還是非常罕見。例如用一些人工智慧的方法讓程式自動學習,做出可以100%篩選出有病的個體的系統。如果要醫生採用的話,一定會被問到為什麼?然而這些參數都是程式自動從資料裡面找出來的,所以也很難回答。不知道是什麼東西,醫生們通常也比較不敢用。但是如果能夠將結果用另一個方式做一次,如決策樹,就比較有可能被接受。
參考資料
[1] 資料探勘 (Data Mining), 作者:曾憲雄、蔡秀滿、蘇東興、曾秋蓉、王慶堯,
http://www.flag.com.tw/book/bookinfo.asp?bokno=F7899
[2] Captain America: The Winter Soldier,
http://en.wikipedia.org/wiki/Captain_America:_The_Winter_Soldier
[3] Person of Interest (TV series),
http://en.wikipedia.org/wiki/Person_of_Interest_(TV_series)
[4] Optical character recognition,
http://en.wikipedia.org/wiki/Optical_character_recognition
[5] MD5, http://zh.wikipedia.org/wiki/MD5
[6] 全民健康保險研究資料庫, http://nhird.nhri.org.tw/
[7] 個資資料的去識別化–資料加密與遮蔽, 勤業眾信聯合會計師事務所企業風險管理服務 / 林彥良經理、林錦龍副理【勤業眾信通訊2014年03月號】,
http://www.deloitte.com/view/tc_TW/tw/41932/46531/pri/48b29a37bd664410VgnVCM2000003356f70aRCRD.htm