作者:楊德倫 / 資策會數位教育研究所數位人才培育中心講師
Transformers是一種深度學習的神經網路模型架構,主要用於自然語言處理(NLP,Natural Language Processing),完成文本分類、資訊擷取、問答、摘要、翻譯、文本生成等任務,提供BERT、GPT-2、RoBERTa、T5等支援100種以上語系的預訓練模型,讓開發者能夠直接使用,或透過微調(fine-tune)來進行客製化。
Simple Transformers是基於Transformers的一種函式庫,可以讓使用者快速地訓練出自定義的語言模型。本文將使用Simple Transformers來建立一個多元(multi-class)情緒分類模型,協助開發者完成未知語料的情緒分類任務。
前言
過去在處理序列(Sequence)型態的資料(如文字、圖片、影音等)上,最常見的是遞歸神經網路(RNN,Recurrent Neural Network)架構,按照序列的順序來處理資料,例如常見的 LSTM、GRU 等變化型態,然而 RNN 架構在處理距離過長的序列資料,可能會有系統資源耗費的問題,此時需要一個具有平行處理序列資料的神經網路架構,於是Transformers在2017年橫空出世,在處理序列資料的效能上,有了大幅的提升與改變。
為了讓開發者能夠使用更簡便的語法來進行訓練,阿姆斯特丹大學(University of Amsterdam)的學生Thilina Rajapakse對Transformers API進行封裝,開發了一個容易上手的函式庫Simple Transformers,在Transformers的使用上,語法簡單卻很有力,程式碼結構一致卻富有彈性,對初學者也很友善。
本文中,我們將整合NTCIR提供的中文情緒對話生成(CECG,Chinese Emotional Conversation Generation)語料,該語料提供了對話、回話文字與相對應的情緒標記,適合幫助我們進行訓練,建立客製化的情緒分類語言模型。
中文情緒對話生成(CECG,Chinese Emotional Conversation Generation)
NTCIR第14屆的短文對話任務(STC-3,Short Text Conversation3),是資訊檢索評估任務之一,其中的子任務「中文情緒對話生成」(CECG,Chinese Emotional Conversation Generation)提供了2019年600,000組與2017年1,100,00組有情緒標記的單輪對話之訓練資料集,給大家使用。原先的資料集使用簡體中文,可以考慮使用OpenCC(Open Chinese Convert)將其轉換成正體中文。

圖1.CECG資料集的部分內容
如圖1所示,每一組單輪對話間,分為[post, label]與[reply, label] post指的是使用者輸入的發話,reply是指對post所作出的回應,label是對應post或reply的情緒標記,值域在0到5之間。0是指其它(Other),1是指喜歡(Like),2是指悲傷(Sadness),3是指噁心、厭惡(Disgust),4是指憤怒(Anger),5是指開心、幸福、高興(Happiness),在圖2中可以清楚了解資料集的結構。
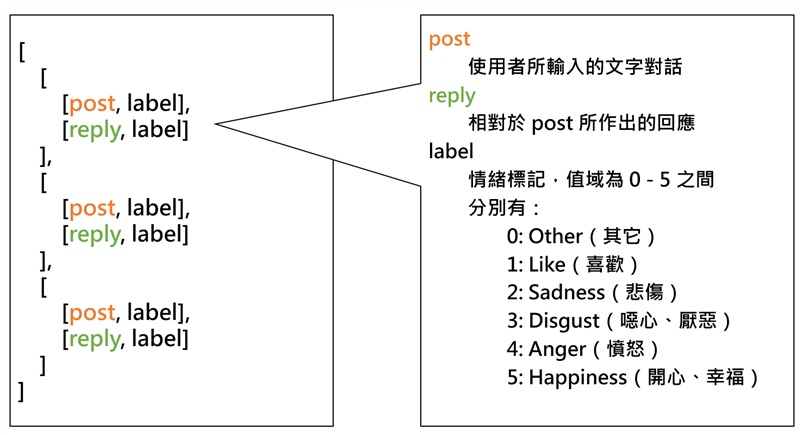
圖2.CECG 資料集的結構
系統環境建置
本文測試環境使用Python 3.8.8版本,作業系統是Windows 10,支援GPU,NVIDIA (R) Cuda compiler driver版本為v11.0,所以需要安裝支援GPU的PyTorch 相關套件:
|
安裝套件 (有 GPU)
|
|
pip install torch==1.7.1+cu110 torchvision==0.8.2+cu110 torchaudio==0.7.2 -f https://download.pytorch.org/whl/torch_stable.html
|
若是電腦沒有GPU,則可以直接安裝CPU版本的PyTorch相關套件,缺點是訓練需要花費非常久的時間:
|
安裝套件 (無 GPU)
|
|
pip install torch==1.7.1+cpu torchvision==0.8.2+cpu torchaudio==0.7.2 -f https://download.pytorch.org/whl/torch_stable.html
|
最後別忘記安裝Simple Transformers套件(官方網站也有提供 conda的安裝方法,可自行前往參考):
|
安裝套件
|
|
pip install simpletransformers
|
語料下載與轉換
可至NTCIR-14 Short Text Conversation Task (STC-3)的網站下載CECG資料集,或是到這裡下載(連結可能隨時失效)。之後轉換格式的資料集,會以整合2019與2017年共170萬組單輪對話(340萬句符合[text,label]格式的資料),檔案名稱為stc3_cecg_2017_and_2019_170w.json,讀者可自行定義:

圖3.將2019與2017年CECG資料集整合後的檔案內容
接下來,需要將資料集轉換成Simple Transformers訓練multi-classclassification時所要求的格式。以下分享簡單的程式碼,有經驗的開發者可自由發揮和修改,剛入門的朋友可以考慮直接使用:
| 程式碼 cecg2data.py |
 |
|
指令
|
|
python cecg2train.py --data=stc3_cecg_2017_and_2019_170w.json --save=train.json
|

圖4.將CECG資料集轉換成train.json,其排版後的預覽結果
訓練情緒分類語言模型
接下來,即將開始訓練模型。在模型參數中,預訓練模型選擇bert,bert在這裡是simple transformers的代碼;bert-base-chinese 是指定支援中文的預訓練模型,其它常見的預訓練模型,可以參考Hugging Face網站,或是Simple Transformers的Classification Specifics頁面;train_batch_size是指每次放入神經網路訓練的樣本數,其值愈高,佔用GPU記憶體愈多,模型收斂更快、學得更好(請參考「梯度下降」),但有可能會發生過度擬合(overfitting)的問題,變成一定要是剛好或是非常接近原始資料,才會被正確預測出來,這會造成模型泛化能力不足,無法對未知的資料進行準確的預測;有些人會使用2的冪來設定 train_batch_size的值,例如1(很少)、2、4、8、16、32、64、128…等,也有人會嘗試出一個特定的值(無論奇數或偶數),把GPU記憶體用到剛好又不會拋出錯誤,一切視需求調整;num_train_epochs是訓練回合數,每一回合都會將原先的資料重新隨機排序(shuffle)後,再切分成數個batches(1個batch的樣本數量,就是 batch size),重新放到神經網路訓練。
隨著訓練資料集大小、文句長度等不同,設定上都會有所不同,學習率(learning rate)也會有影響,但這個不在我們討論範圍,讀者可上網查閱,並視情況調整。可以參考下列的訓練程式碼,依需求修改或增刪:
| 程式碼 train.py |
 |
|
指令
|
|
python train.py --data=train.json
|
|
提醒
|
|
拋出錯誤
RuntimeError: CUDA out of memory.
通常是train_batch_size 設定太高了,造成 GPU 記憶體不足;試著降低數值,如果是以 2 的冪來調整,那就試著向下調整,一次不夠就再降,降到可以正常執行;若是模型預測成效不佳,就提升 num_train_epochs,讓神經網路多學幾回,再回頭評估成效。
|
圖6.輸出模型會儲存在outputs當中的bert-base-chinese-bs-64-epo-3資料夾
預測文字的情緒
完成了語言模型的訓練後,準備開始進行預測,預測的回傳結果會是一個list,代表可以一次預測一個以上的句子,對多個句子進行預測時,回傳的順序也是各個句子的情緒分類結果。有一個需要注意的地方,就是預測時的模型參數設定,通常與訓練時的模型參數設定一致:
| 程式碼 predict.py |
 |
將自訂的「現在 刷 朋友 圈 最大 的 快樂 就是 看 代購 們 各種 直播 。 。 。 。 。」、「你 幹 了 什麼」、「不 愁 吃 , 不 愁 穿 , 不 愁 住 , 不 愁 行 , 還 愁 啥 呢 ?」三句話進行預測,會得到 [5, 4, 3] 的輸出結果,皆為情緒標記的值,5代表happiness,4代表anger,3代表disgust。表1提供了文句的預測結果,大家覺得如何呢?
|
索引
|
文句
|
預測情緒標記
|
標記意義
|
|
0
|
現在 刷 朋友 圈 最大 的 快樂 就是 看 代購 們 各種 直播 。 。 。 。 。
|
5
|
happiness
|
|
1
|
你 幹 了 什麼
|
4
|
anger
|
|
2
|
不 愁 吃 , 不 愁 穿 , 不 愁 住 , 不 愁 行 , 還 愁 啥 呢 ?
|
3
|
disgust
|
表1.文句的預測結果
後記
本文使用了Simple Transformers取得預訓練模型,提供了訓練與預測的方法,期許協助開發者或使用者完成下游任務,進一步檢視未分類的文句,提供合適的情緒標記,然而文章尚有不足之處,例如資料集尚未去除重複或無意義對話,以及尚未進行模型成效評估等,篇幅有限,無法詳細說明,讀者在訓練自訂的情緒分類模型時,務必進行完善的資料預處理,以及評估訓練完畢後的語言模型,相信對下游的分類任務上,會有正面、實質的幫助。
參考資料
[1]自然語言處理:https://zh.wikipedia.org/zh-hant/%E8%87%AA%E7%84%B6%E8%AF%AD%E8%A8%80%E5%A4%84%E7%90%86
[2]Simple Transformers:https://simpletransformers.ai/
[3]範例程式碼:https://github.com/telunyang/python_multiclass_classification
[4]Hugging Face:https://huggingface.co/
[5]Multiclass, Multilabel以及Multitask的區別:https://cynthiachuang.github.io/Difference-between-Multiclass-Multilabel-and-Multitask-Problem/
[6]Epoch, Batch size, Iteration, Learning Rate:https://medium.com/%E4%BA%BA%E5%B7%A5%E6%99%BA%E6%85%A7-%E5%80%92%E5%BA%95%E6%9C%89%E5%A4%9A%E6%99%BA%E6%85%A7/epoch-batch-size-iteration-learning-rate-b62bf6334c49
[7]transformers:https://github.com/huggingface/transformers
[8]NTCIR-14 Short Text Conversation Task (STC-3):http://sakailab.com/ntcir14stc3/