作者:洪嘉駿/臺灣大學計算機及資訊網路中心程式設計組幹事
以每周都有一篇「最新消息」為例,介紹如何以Python搭配Beautiful Soup修改大量格式相似靜態網頁版型。考量到實際的使用情境,本文將會先準備一個新的網頁模板,再將「最新消息」的標題與內文等填入其中。此外,搭配檔案走訪,使用者只需指定輸入與輸出目錄,即可讓檔案自動輸出至輸出目錄,並且使其檔案結構與輸入目錄一致。
前言
即便在動態網頁隨處可見的今日,依然有部分網站選擇使用純靜態的網頁。也許是該網站不需經常更新,也許是考量到靜態網頁安全性較高,也許是網站創建之初即使用靜態網頁,而後續維護者又直接承襲下來。無論如何,如果你的網站是靜態網頁,又剛好想要擷取其中內容,那本文可能可以幫你省下不少時間。
試想,若有個網站,每周都會新增一篇最新消息,而新增最新消息的方法,即是新增一頁靜態網頁,如圖一。經年累月下來,最新消息的頁面數量肯定非常驚人。如果今天想將這個網頁的版型稍作修改該怎麼辦呢?簡單的情況或許可以用搜尋與取代,搭配regular expression完成,但若要作稍微複雜的修改呢?那就來試試Beautiful Soup吧!
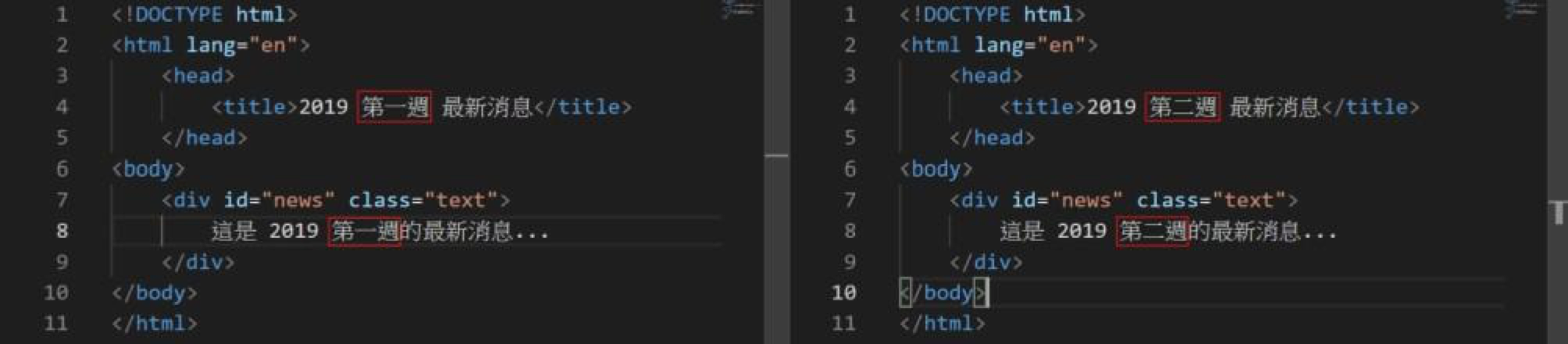
圖一:每週的最新消息版型雷同,只有內容不同。左邊範例為第一週的最新消息,右邊範例為第二週的最新消息。
Beautiful Soup簡介
Beautiful Soup是一個Python的library,可以幫助我們解析並操作HTML文件。透過Beautiful Soup,我們可以走訪元素、搜尋元素、修改元素內文、擷取元素、新增子元素,還可以替元素加上HTML attribute等。本文的範例使用的版本是Beautiful Soup 4。
Beautiful Soup 4可以透過pip安裝,指令為「pip install beautifulsoup4」,詳細安裝方法在此不贅述。
建立Beautiful Soup物件
安裝好Beautiful Soup後,我們建立一個最新消息的範例,並將此範例的HTML字串傳入Beautiful Soup的constructor,同時指定使用'html.parser'這個parser,即可建立Beautiful Soup物件,如圖二。我們將建立好的物件命名為soup,後續將透過soup這個物件來操作這份HTML。
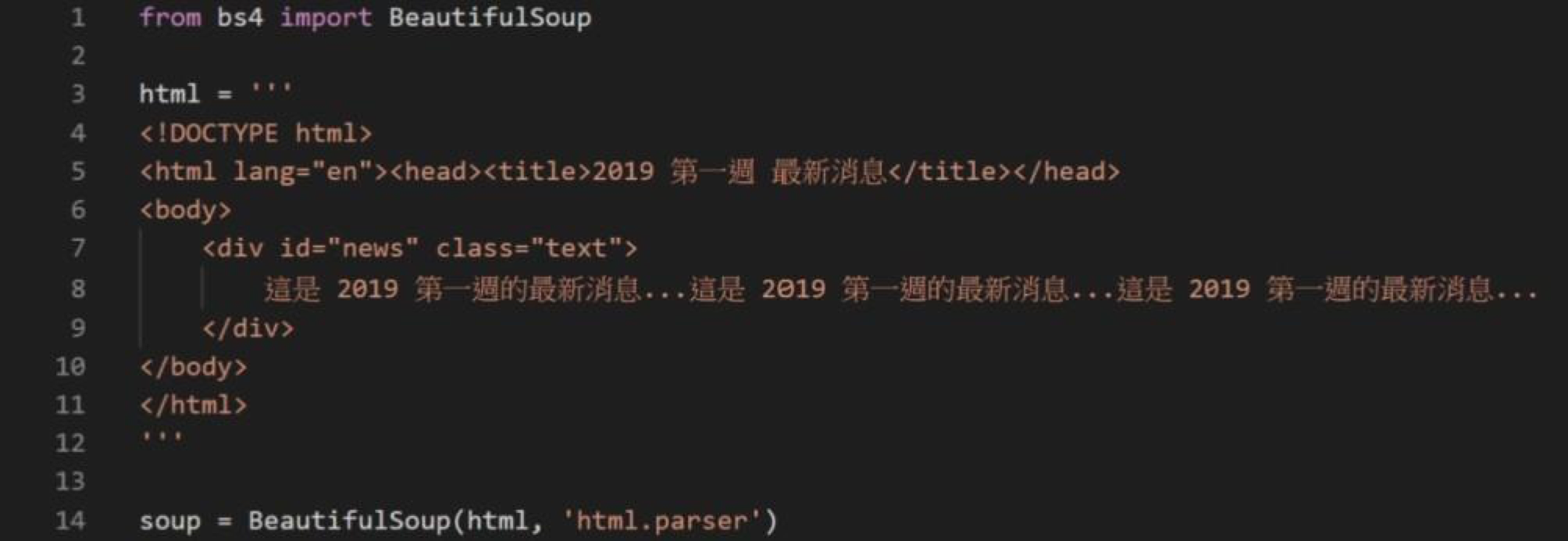
圖二:建立Beautiful Soup物件
找出目標元素
一旦成功建立Beautiful Soup物件後,就可以透過find()這個方法找出我們想要的元素。
我們要找的目標有二個,第一個是<title>...</title>,第二個是「最新消息」區塊(<div id="news" class="text">...</div>)。
觀察後可以發現,因為整份檔案只有一個<title>...</title>,所以我們可以用元素的名稱搜尋,亦即直接搜尋title,語法如圖三所示。
那如果我們想要找到「最新消息」區塊,是否也可以直接搜尋div呢?以這個範例來說可以,因為這個範例中只有一個div,但通常正式的網頁都不只一個div,所以我們無法只靠搜尋div,就精準地定位到「最新消息」區塊。因此,我們要靠搜尋id來定位到「最新消息」區塊,如圖三所示。

圖三:依元素名稱搜尋和依id搜尋
find()這個方法的搜尋條件可以是HTML元素的名稱、id、class,或是其他屬性等,詳細說明條件請參閱官方說明文件。
準備模板
為何要準備模板?修改版型有兩個方法,一個是直接修改soup物件,另一個是先擷取soup物件中的資料,再將資料填至新模板中。實際要用哪種方法要視情況而定。如果是細微的修改,例如在最新消息前插入一個div,可以選擇用前者,因為可以省下準備模板的時間。如果是較大的修改,可以先準備模板,因為習慣上,大幅度的修改,本來就很可能會先設計一個模板做為參考。有了模板後,我們就能透過Beautiful Soup將模板變成Beautiful Soup物件,有了Beautiful Soup物件後,我們就能透過append()、replace_with()等方法將資料填入模板中。如此一來,不僅可以先一窺新版型的樣貌,還可省去透過soup物件大量修改HTML的時間,一舉兩得。
本文採用準備模板的方法,因此,我們先創建一個模板,並命名為template.html。假設我們希望將資料填入模板中的<div id="content"></div>元素中,那我們必須先在模板中寫好這個<div>,並且賦予它一個id,以便作為我們搜尋的條件。模板如圖四所示。
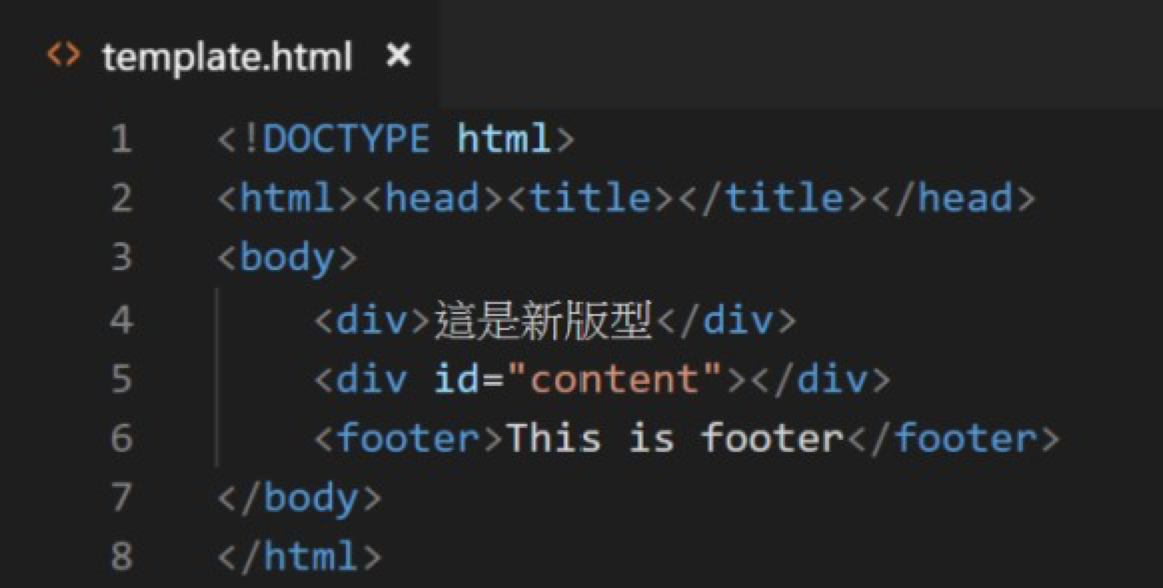
圖四:template.html。模板的HTML。在模板中預先寫好<div id="content"></div>,供我們將資料填入其中。
模板的HTML檔準備好後,我們用先前的方法,將模板變成Beautiful Soup物件,如圖五所示。本文最後會以檔案讀取的方式讀取template.html,在這裡,我們暫且不用檔案讀取的方式讀取template.html,而是將template.html的內文直接複製到程式碼中。
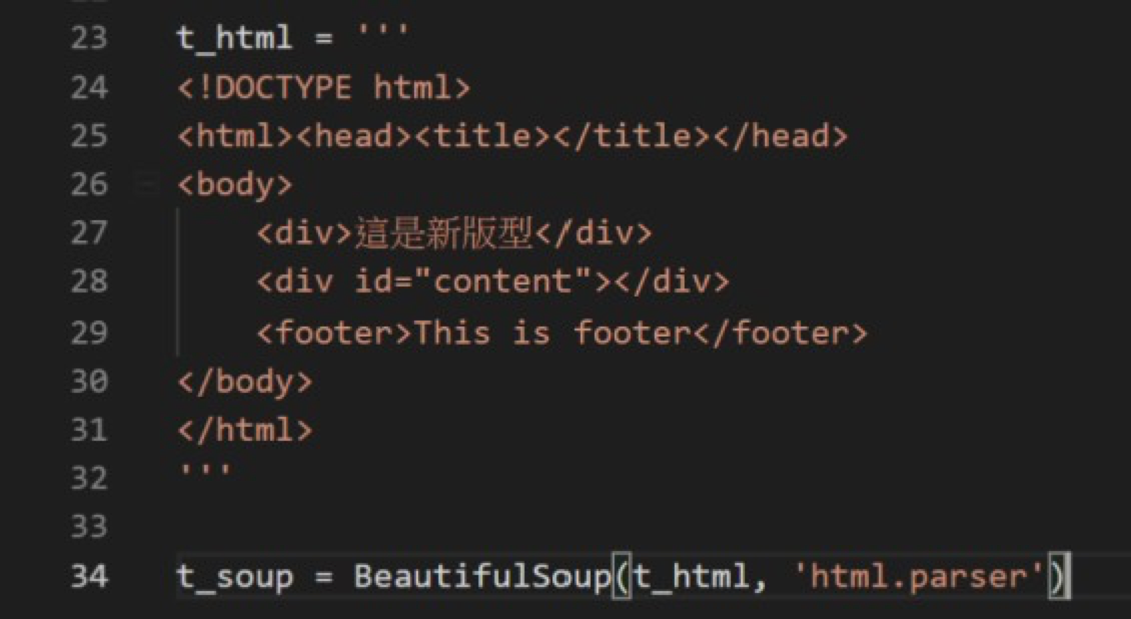
圖五:將template.html的內文直接複製到程式碼中,並建立成Beautiful Soup物件。
將資料填入模板中
要移入模板的資料有兩部分,第一部分是<title>,第二部分是<div id="news" class="text">...</div>,如圖六所示。根據觀察,我們發現<title>的部分可以用replace_with(),以舊的<title>取代模板中的<title>。而最新消息內文的部分,我們可以用append(),將整個<div id="news" class="text">...</div>附加到<div id="content"></div>元素中。詳細程式碼如圖七所示。

圖六:資料移動示意圖。左邊為舊網頁,右邊為模板,我們希望將左邊的資料移至右邊新模板中。
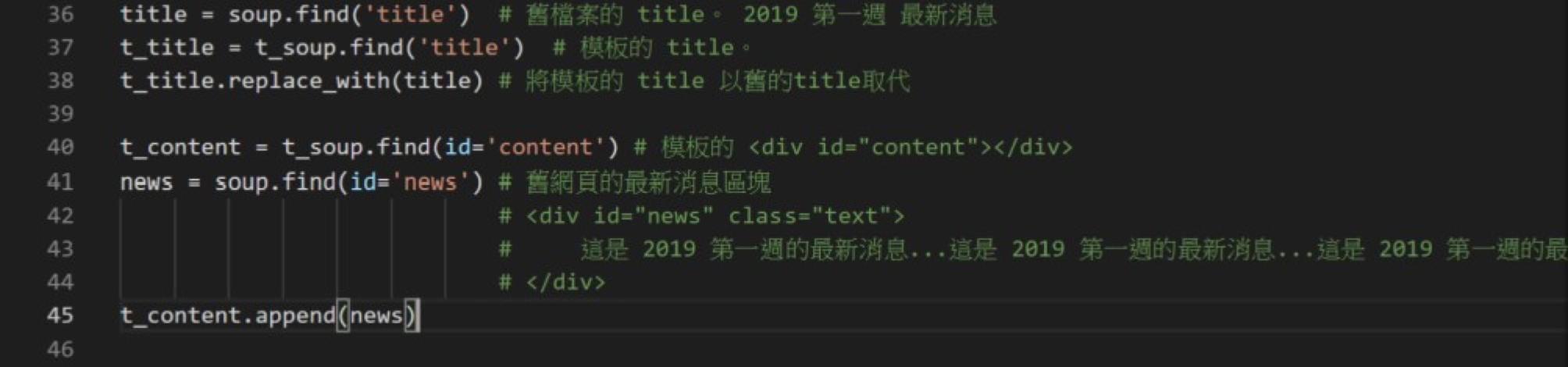
圖七:將舊資料移至新模板中的程式碼
輸出
我們已經成功將資料從舊網頁中擷取出來,並放入新模板中,但我們要怎樣才能看到操作好的HTML呢?
如果想要得到操作好的HTML字串,可以直接對Beautiful Soup物件調用str()即可,如:str(t_soup)。但這樣的輸出結果是尚未prettify的結果。
Beautiful Soup提供了一個方法可以將HTML prettify,直接讓Beautiful Soup物件調用prettify()即可,如:t_soup.prettify(),見圖八。
將Beautiful Soup物件輸出成字串後,我們就能以Python的檔案讀寫方式,將HTML字串存檔。檔案讀寫的方法在此不贅述,文末附上詳細程式碼。
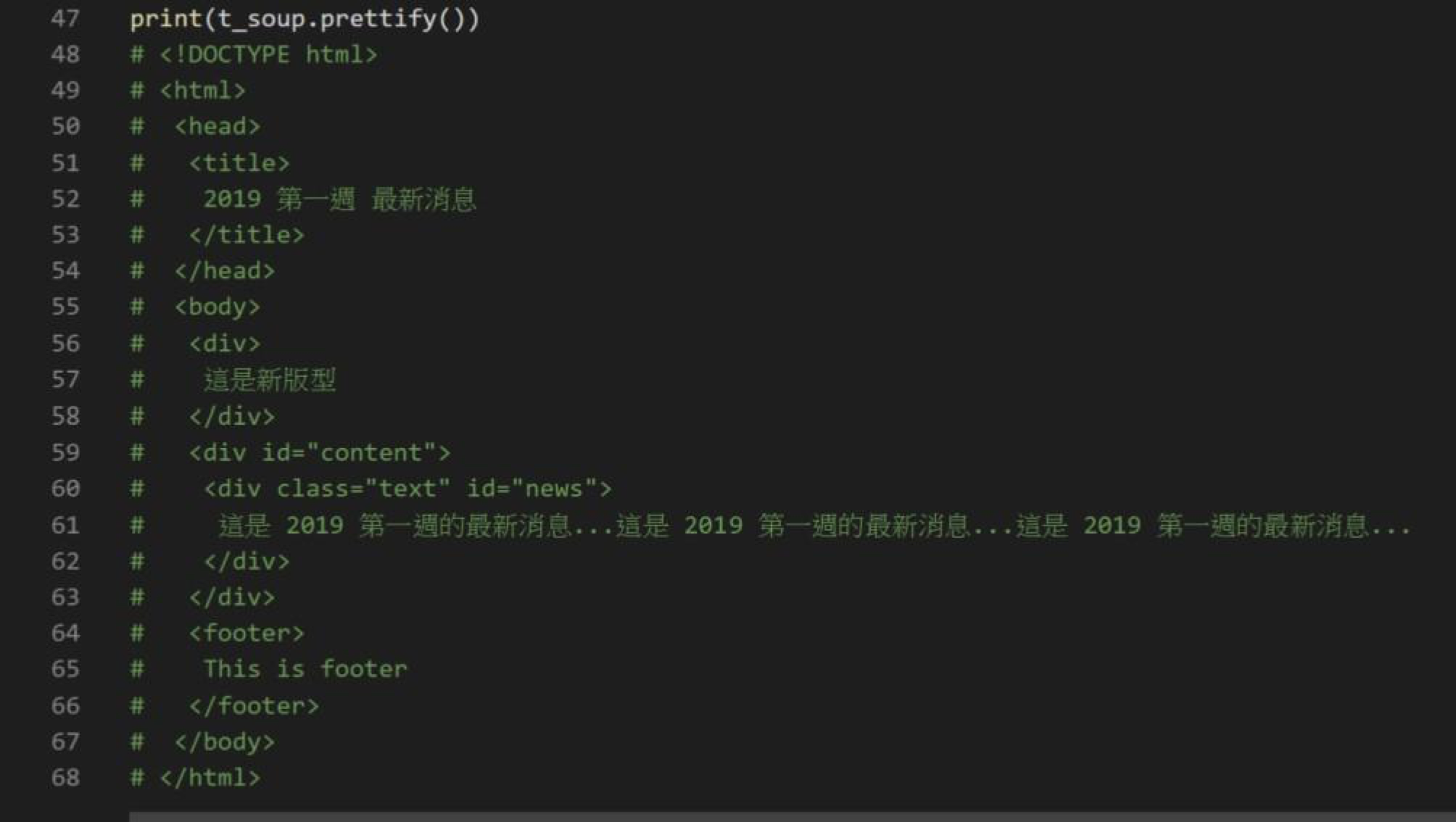
圖八:輸出結果
檔案走訪
透過上述的範例,我們已經知道如何用Beautiful Soup操作HTML了,但如果我們只能用手動的方式,將每份檔案的HTML貼到我們的script中,那這樣豈不是太沒效率了?真實的狀況通常是,一個目錄中可能有許多子目錄,而子目錄中又有許多份html檔,如/2018/news_2018_01.html、/2019/news_2019_01.html、/2019/news_2019_02.html等,如圖九。
圖九:來源檔案的檔案結構
因此,在此專案的根目錄下,創建一個inputfiles目錄,讓我們可以將所有來源檔案放入其中,並針對這個目錄進行檔案走訪。
我們希望我們的程式能自動走訪inputfiles目錄,自動抓出此目錄與其子目錄底下的html檔,抓出html檔後,再自動將資料與模板結合,結合完畢後,再自動存檔,且存檔時的檔案結構,必須與來源目錄的檔案結構一致。
在此範例中,程式會自動將輸出的檔案放至outputfiles目錄下。待程式執行結束後,outputfiles目錄下的檔案結構會和inputfiles目錄相同,如圖十。注意,本範例執行時,並不會自動先清空outputfiles目錄,若有需要,請手動清空。另外,若在程式執行時,outputfiles目錄下已有同名檔案,則程式會覆蓋之。
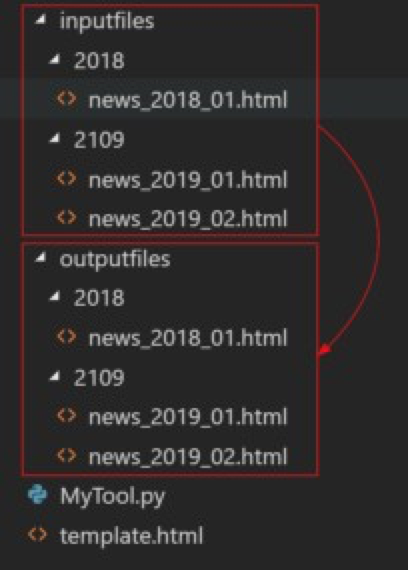
圖十:程式自動在outputfiles目錄下產生檔案,其檔案結構與inputfiles目錄相同。
具體而言,檔案的走訪究竟要如何辦到呢?我們可以用Python的os.walk()來達成。用os.walk()走訪目錄時,我們可以取得當前目錄、當前目錄下的所有目錄,與當前目錄下的所有檔案名稱。在此,我們不用取得當前目錄下的所有目錄,因為os.walk()會自動替我們走訪,只需要知道當前目錄與檔案名稱,就可以把這兩者組成相對於inputfiles的相對路徑。有了相對於inputfiles的相對路徑後,就能透過open()來讀取檔案。當然,我們還必須取得相對於outputfiles的相對路徑,以供我們存檔之用,相對於outputfiles的相對路徑的取得方法如十一所示。
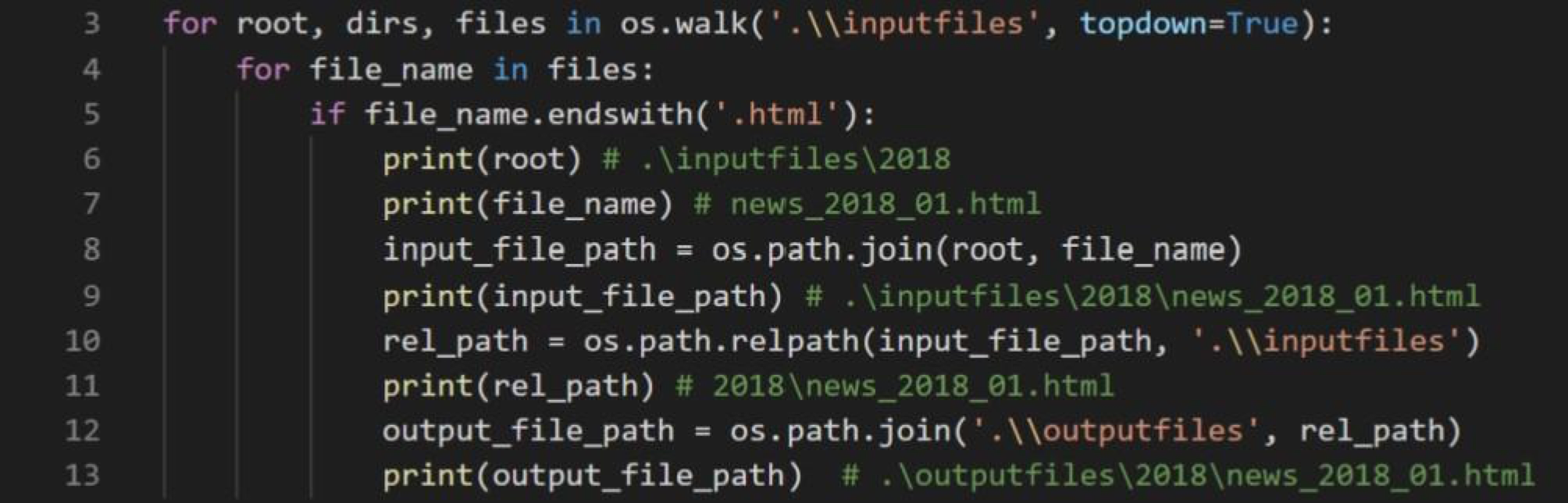
圖十一:os.walk()使用方法與相對路徑取得之範例。input_file_path可供我們讀檔,output_file_path可供我們存檔。
最後,我們要將以上的範例全部組合起來。檔案結構、最新消息範例,模板,請見圖十二,完整程式碼請見圖十三。
為了增加可維護性,我們將「處理單一檔案」的部分獨立出來,寫成一個function,並命名為do。我們只需要傳入兩個參數,一個是來源檔案的路徑,另一個是輸出檔案的路徑,這個function就能幫我們將「這個檔案」處理完畢。當然,也要指定template.html的路徑,不過在此是直接hard code在do裡面。
有了do這個function之後,只要將它與前面提到的檔案走訪結合,就能自動走訪與處理所有檔案,進而達到修改大量靜態網頁版型的目的。
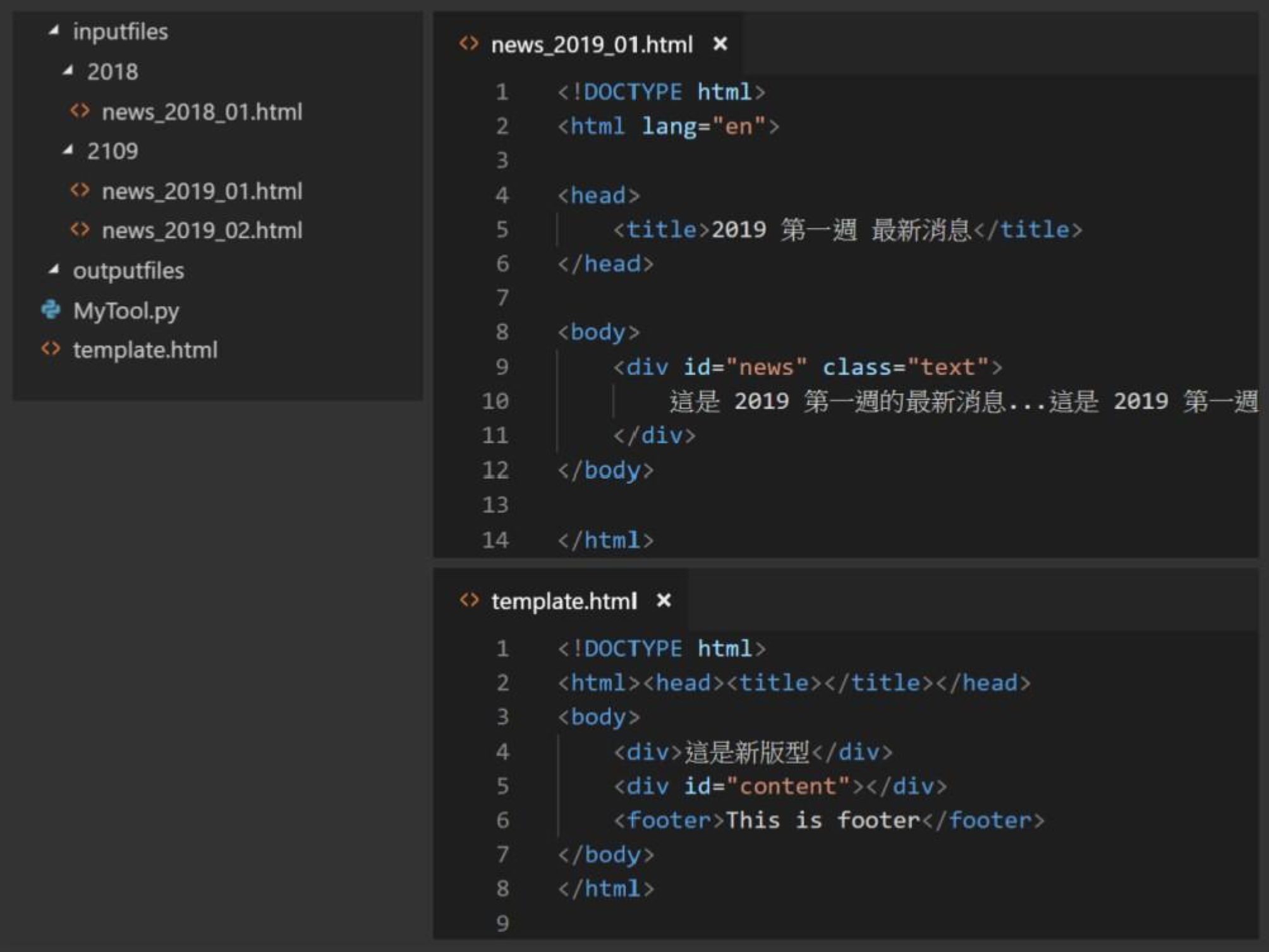
圖十二:檔案結構、最新消息範例與模板
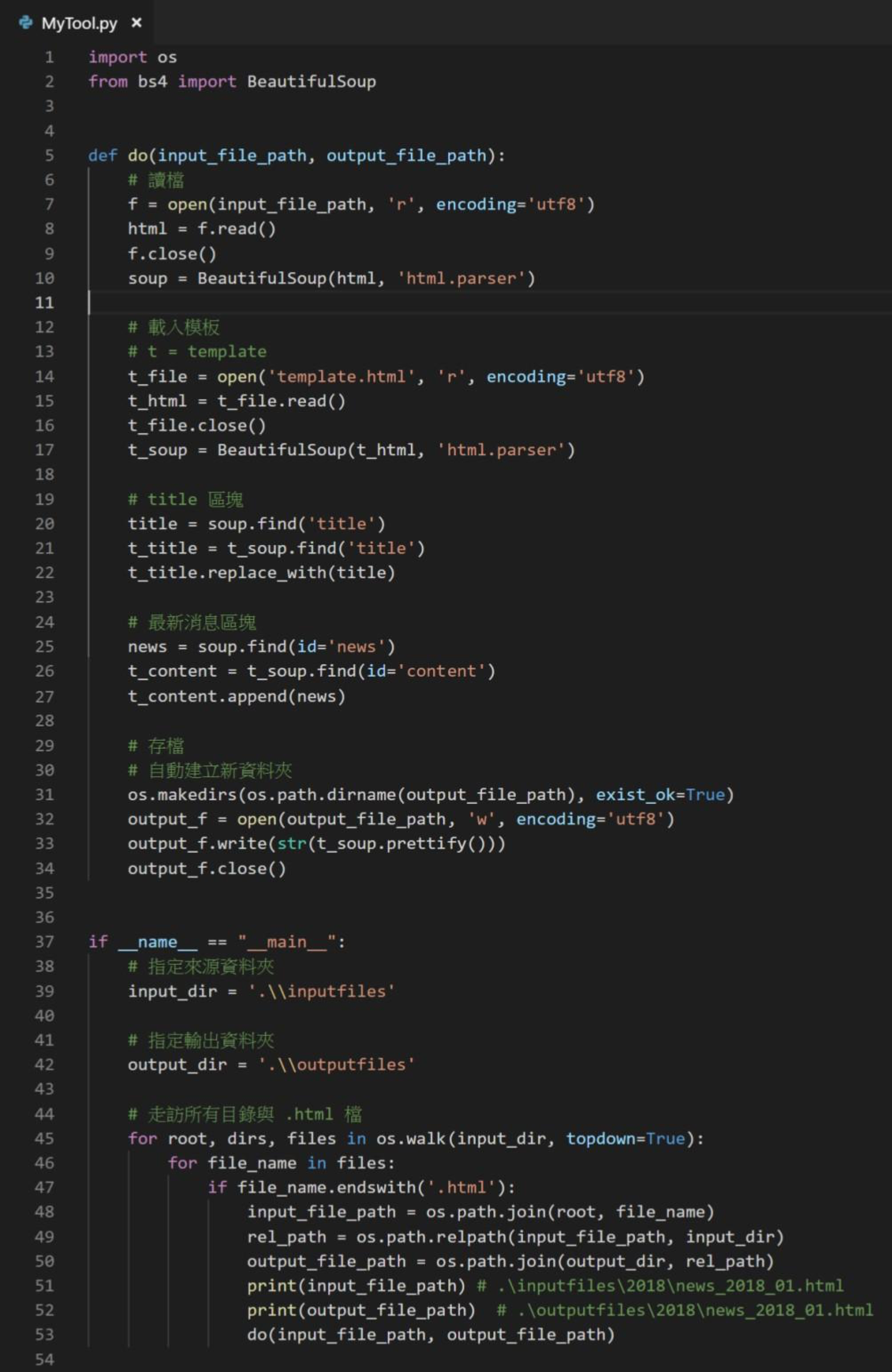
圖十三:完整程式碼
本文雖然從實際的角度出發,以真實可能遇到的狀況作為範例,但一般而言,如果有類似「最新消息」的需求,或許可以考慮使用內容管理系統。如果擔心內容管理系統有安全性問題,或許可以將內容管理系統的內容匯出成靜態網頁後,再將靜態網頁上線。如此一來,既能避免內容管理系統的安全性問題,還能避免靜態網頁更改版型時所造成的困擾。
參考資訊
Beautiful Soup Documentation:https://www.crummy.com/software/BeautifulSoup/bs4/doc/#