作者:林淑芬 / 臺灣大學計算機及資訊網路中心教學研究組程式設計師
本文乃接續上一期的「資料探勘SO EASY」一文,利用IBM/SPSS Modeler軟體的三大自動建立模型功能,包括自動分類、自動數值、自動叢集,以實際案例和實際操作的方式,說明如何快速自動建立多個資料探勘模型,並以不同的準則來評估分析,以選取最佳模型,讓使用者得以輕鬆快速地進行資料探勘。
前言
面臨巨量資料時代的來臨,無論是科學及醫學上的研究,或是政府部門及企業應用領域,專家們都以資料分析作為公司或組織發展方向與決策支援的重要工作。資料探勘的應用範圍遍及各個領域,包括金融保險業的信用評等、呆帳分析、保險詐欺偵測、持卡人的購買行為,零售製造業的分店設點區位分析、市場區隔、DM名單、促銷商品組合,醫療生技業的臨床病症分析、基因圖譜比對、預防醫學分析等,都是希望從堆積如山的資料,利用自動或半自動的方式,發掘出隱藏在資料中的有用資訊。
資料探勘的過程是需要建立多個模型,然後加以評估分析。本文將接續上一期的資料探勘SO EASY一文,利用IBM/SPSS Modeler軟體的實際操作,說明如何快速自動建立多個資料探勘模型並加以評估分析。Modeler自動建模最好用的地方就是它會根據你的資料以及模型限制,提供適合探勘的模型,不符你所使用資料的模型就會呈現無法選取的灰色。至於自動建立模型的功能大致可分為以下三類:
1. 自動分類(Auto Classifier):自動分類所要預測的輸出目標是類別型態的變數,可用的模型包括Neural Net、C&R Tree、QUEST、CHAID、C5.0、Logistic Regression、Decision List、 SVM、 Discriminate等模型。
2. 自動數值(Auto Numeric):自動數值模型可幫助我們預測數值的目標,可用的模型包括Regression、General Linear、Neural Net、C&R Tree、QUEST、CHAID、Linear等模型。
3. 自動叢集(Auto Clustering):自動叢集可幫助我們自動分群,將同質的資料集群在一起,可用的模型包括K-Means、Kohonen、TwoStep模型。
接下來我們將分別以這三大類自動模型舉例,說明如何以SPSS Modeler自動建立模型和評估分析的步驟。
一. 自動分類建模:客戶信用風險評估模型
本範例檔Risk.xlsx是有關客戶信用評估的資料,包括的欄位有ID、AGE、INCOME、MARITAL、NUMKIDS、NUMCARDS、HOWPAID、MORTGAGE、STORECAR、LOANS、RISK等,其中信用欄位RISK的值又分為good risk、bad profit和bad loss三種。
資料探勘的過程如下:首先設定檔案來源【EXCEL】節點,選擇檔案Risk.xlsx。
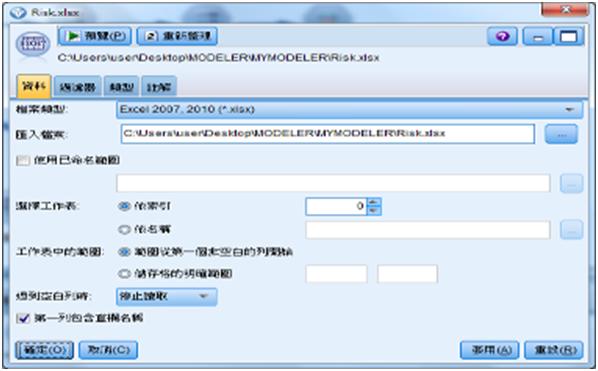
圖1 檔案來源【EXCEL】節點
然後再設定【過濾器】節點,過濾掉ID欄位。
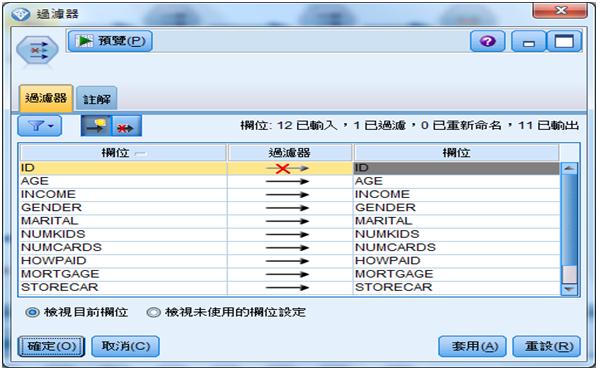
圖2 設定【過濾器】節點
接著,利用【導出】節點產生SUMDEBT和CHILDREN兩個衍生欄位,SUMDEBT是三項負債的總合LOANS+NUMCARDS+STORECAR,而另一個衍生欄位CHILDREN則是當NUMKIDS>0時為true,否則為false。再來是設定【分割區】節點,訓練區為70%,測試區為30%。最後我們再產生一個GoodProfit新欄位,當RISK為good profit時為true,其他如bad profit或bad loss則為false。
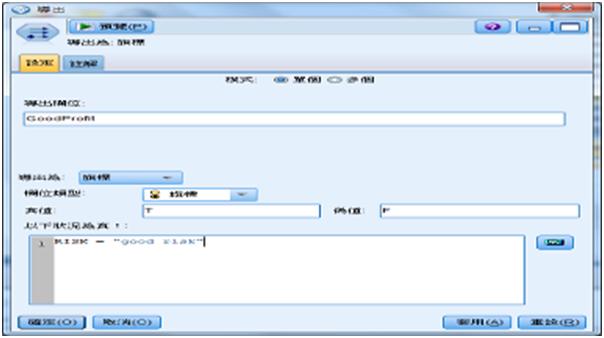
圖3 利用【導出】節點產生新欄位
在自動建模前需利用【類型】節點進行欄位角色的設定。目標欄位必須是類別型態變數。所以我們將GoodProfit欄位的角色設成「目標」,RISK欄位的角色設成「無」,其他欄位的角色全設成「輸入」。
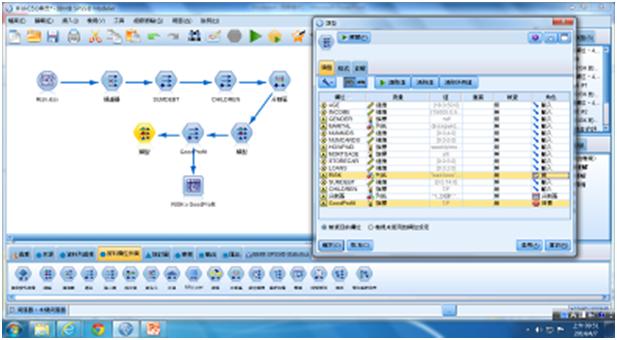
圖4 欄位的角色設定
接著便可以開始建模,從下方建模面板選取【自動分類器】,設定你要使用的模型個數(default為3),以及排序依據(default為整體準確性)。
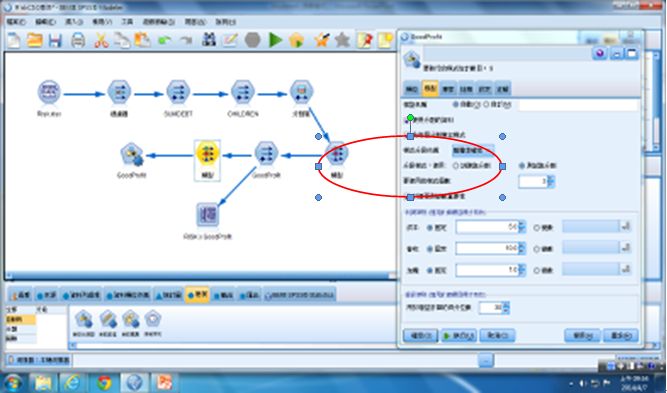
圖5 自動分類模型個數及設定排序準則
Modeler自動建模最好用的地方是它會根據你的資料以及模型限制,提供適合探勘的模型,讓你選擇使用,不符你所使用資料的模型就會呈現無法選取的灰色。
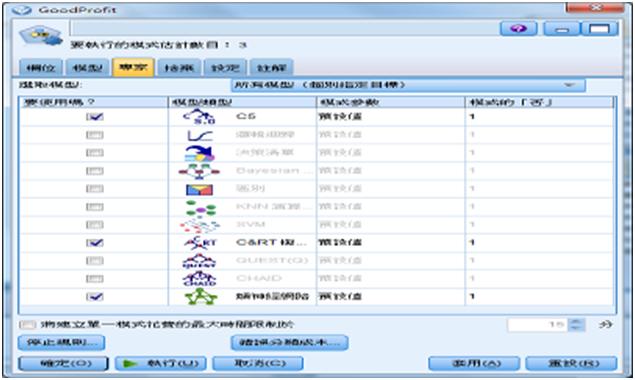
圖6 選取合適的分類模型
很快地便產生下圖的三個分類模型讓我們同時比較,這時我們選擇的排序評比準則是「提昇」。當然也可依原先預設的「整體精確度」來排序。
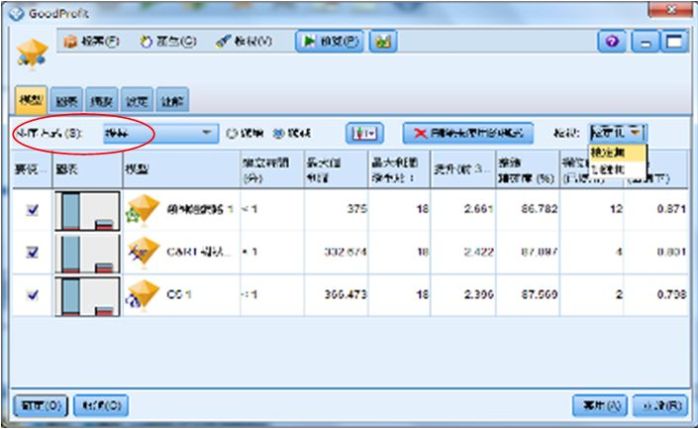
圖7 產生三種分類模型
接著選取「圖表」標籤,可看到如下實際值和預測值的比較圖,也可進一步產生評估圖,包括增益圖(Gains)、回應圖(Response)、提昇圖(Lift)、利潤圖(Profit)、投資報酬(ROI)、接收端運作性質圖(ROC) 等6種評估圖。評估的方式是先按照目標預測值和信賴度排序,然後切成同等大小的100份,再依據不同的評估準則劃出累積圖,常用的有增益圖(Gains)和提昇圖(Lift),增益圖的定義是(百分比的命中個數/總命中個數) × 100% ,而提昇圖的定義則是(百分比的命中個數/百分比的紀錄筆數)/(總命中個數/總紀錄筆數),其中的命中(Hit)是指某特定的結果值,通常目標欄位若是旗標型態則預設為true,目標欄位若是列名(nominal)型態則預設為第一項的值,但這是可改變的。
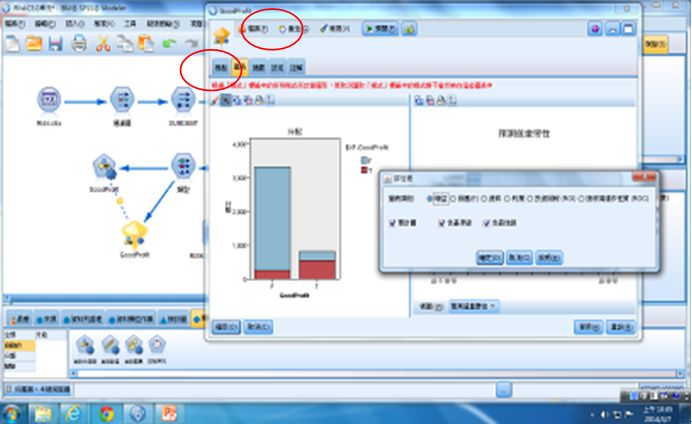
圖8 產生增益圖並含最佳線
以下便是最後產生的三種模型的增益圖,選出最佳模型的原則很簡單,越接近最佳線的模型當然是越好了。
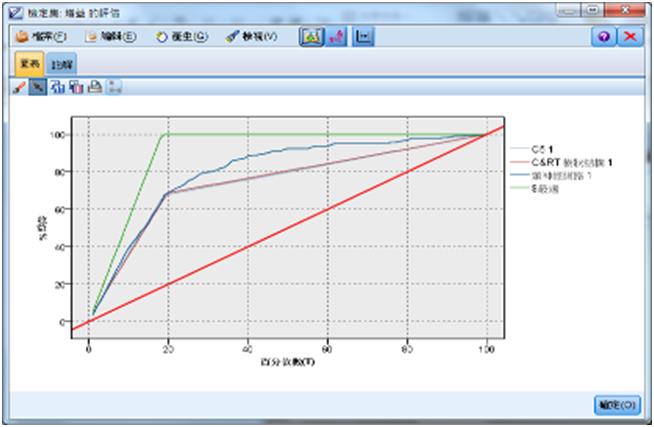
圖9 三種分類模型的增益圖比較
二. 自動數值建模:客戶使用長途電話的預測
自動數值模型可幫助我們預測數值的目標,本範例檔customer_offers.sav是SPSS統計軟體的資料檔,包括很多客戶基本資料,其中我們想要預測的數值欄位是長途電話分鐘數,而輸入則包括Size of Hometown、Gender、Age、Years of Education、Union Member、Years with Current Employee、Household Income in Thousands、Marital Status、Number of People in household等9個欄位。
資料探勘的過程首先設定檔案來源【統計檔案】節點,選擇customer_offers.sav檔案。
圖10 檔案來源【變數檔案】節點
在自動建模前需利用【類型】節點進行欄位角色的設定。我們設定Long distance over tenure為「目標」欄位,9個「輸入」欄位,其他欄位的角色全部設成「無」。
圖11 欄位的角色設定
接著便可以開始建立模型,從下方建模面板選取【自動數值】的節點,選取你想要使用的模型,若不符你所使用資料的模型,或者礙於模型的限制,圖形就會呈現無法選取的灰色。
圖12 選取合適的數值模型
很快地便產生如下圖最佳的三種模型評估報表讓我們同時比較,這裡我們選擇的排序準則是「相關係數」。 自動數值建模提供3種常用的數值模型評比準則:
1. 相關係數(Correlation)—目標值和目標預測值之間的相關係數,最好在0.8以上。
2. 使用的欄位數量(Fields)—最好是在10個以下。
3. 相對誤差(Relative Error)—觀察值對預測值的變異數除以觀察值對平均數的變異數,相對誤越低越好,最好在1以下。
圖13 產生三種最佳的數值模型
接下來我們按下CHAID模型那列的圖表,就可得到觀察目標值和目標預測值的散佈圖。
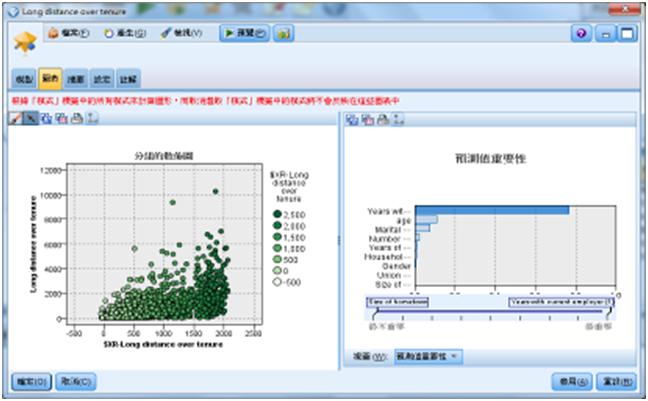
圖14 觀察值和預測值的散佈圖
最後我們打開CHAID模型金磚,可看到CHAID模型規則組的第一層,對數值目標而言,是無法產生和自動分類一樣的評估圖,模型是預測某群組目標欄位的平均和作用,作用(Effect)則是指此群組平均和上一層平均的差。例如,規則是根據和目前雇主一起工作的年數而定,平均是符合此項規則的人長途電話分鐘數平均,例如第一規則組的平均是173.618分鐘,作用是-558.565分鐘,是指目前工作未滿一年的人的平均,和上一層,即全部人平均的差。
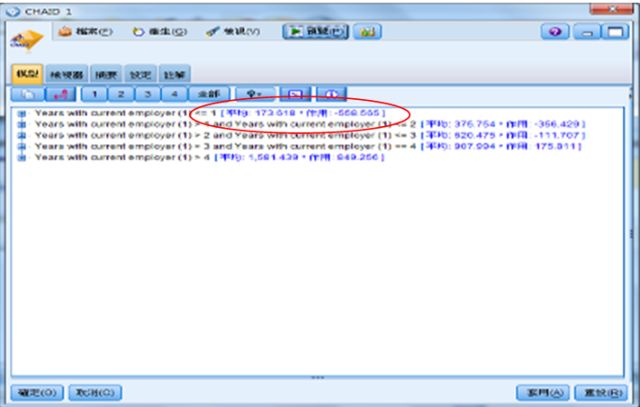
圖15 CHAID模型的規則組第一層
繼續打開CHAID模型的第二層如下圖,作用530.72是指此群組平均和上一層平均的差,例如2112.159 – 1581.439=530.72。只有終端的分支點才可以看到箭頭及符合那個節點規則的預測平均值2112.159及資料筆數147。
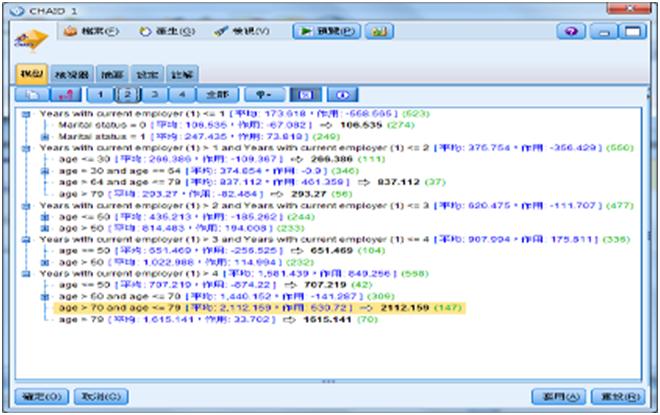
圖16 CHAID模型的規則組第二層
三. 自動叢集建模:電信公司的客戶分群
集群分析就是將異質的群體區隔,分成一些同質性較高的子群組或叢集,不需要事先定義好該如何分類,也不需要訓練組資料,而是靠資料自身的相似性集群在一起,最常使用在市場區隔的應用上。本範例檔churn.txt是電信公司的客戶資料,包括的欄位有ID、LONGDIST、international、LOCAL、AGE、SEX、Marital Status、Children、Estimated Income、Car owner、CHURNED等,其中CHURNED欄位又分為仍留在公司者Current、志願離開公司者Vol和被迫離開公司者Invol三類。
資料探勘的過程首先是設定檔案來源【變數檔案】節點,選擇檔案churn.txt。
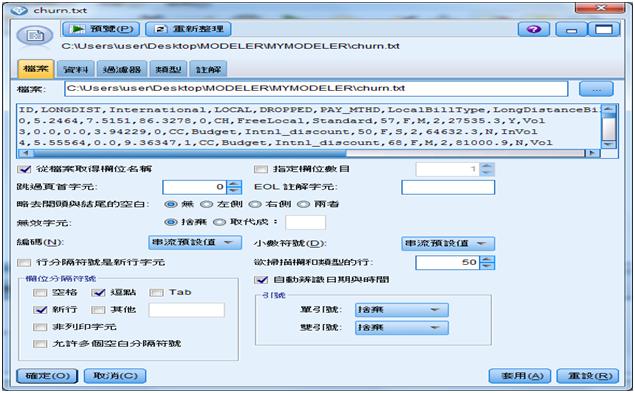
圖17 檔案來源【變數檔案】節點
在自動建模前需利用【類型】節點進行欄位角色的設定。我們設定長途、國際、和市內電話三個「輸入」欄位:LONGDIST、international、LOCAL,不需「目標」欄位,其他欄位的角色全部設成「無」。
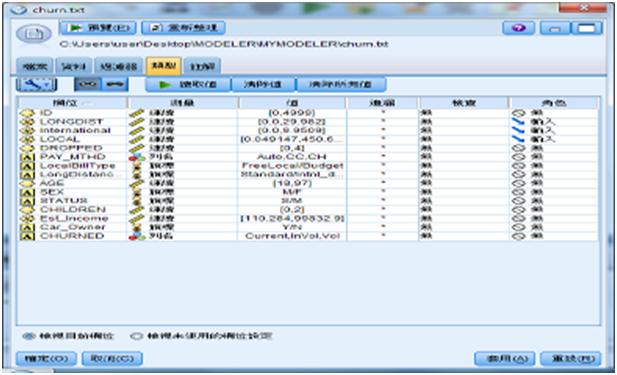
圖18 欄位的角色設定
接著便可以開始建模,從下方建模面板選取【自動叢集】,設定你要使用的模型個數(default為3),以及排序準則依據(default為Silhouett係數)。
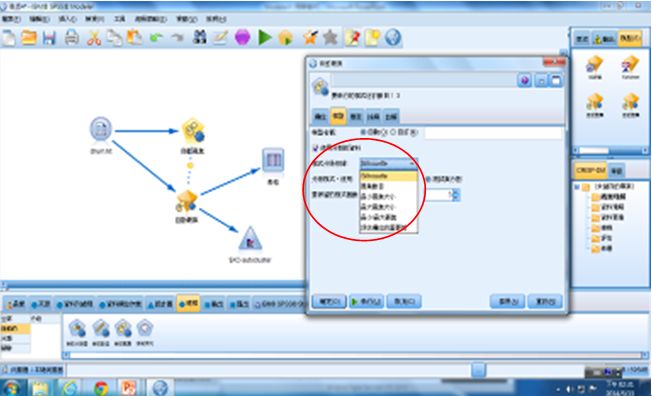
圖19 設定自動叢集模型個數及準則排序
Modeler自動叢集提供Kohonen、K-Means和TwoStep三種探勘的模型。
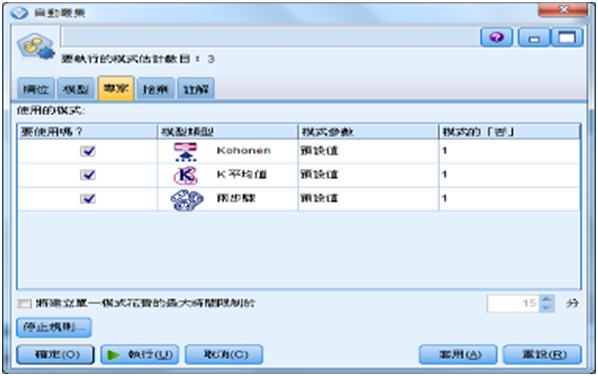
圖20 提供的三種叢集模型
很快地便產生下圖的三種集群模型讓我們同時比較,我們選擇的排序評比準則是「Silhouett係數」。Silhouett係數是用來比較集群模型的準則,計算每筆紀錄(B-A)/max(A,B)的平均值。A是指每筆紀錄到其所屬叢集中心的距離,B是指每筆紀錄到其最近但不屬於的叢集中心的距離。Silhouett係數範圍在-1(非常差的模型)和1(非常好的模型)之間,可丟棄Silhouett係數為負值的模型。我們可以看到自動叢集節點選出的結果,Silhouett係數最佳的是K-Means模型。
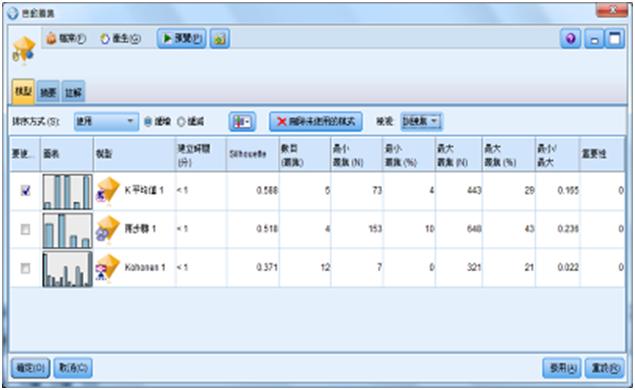
圖21 最佳的是K-Means模型
按下K-Means模型的「圖表」,可進一步看到K-Means模型較詳細的描述。共產生5個叢集,叢集品質良好,最大叢集佔30.0%,最小叢集佔4.9%。
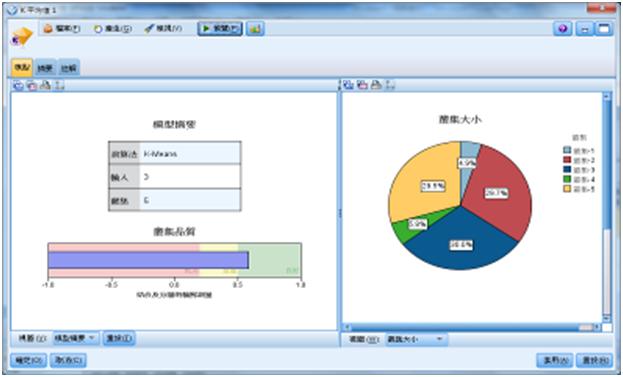
圖22 K-Means模型產生5個叢集
最後來探討K-Means模型,看看CHURNED欄位在叢集中的分配圖,從下圖中我們發現被迫離開公司者Invol都被分群到叢集5。
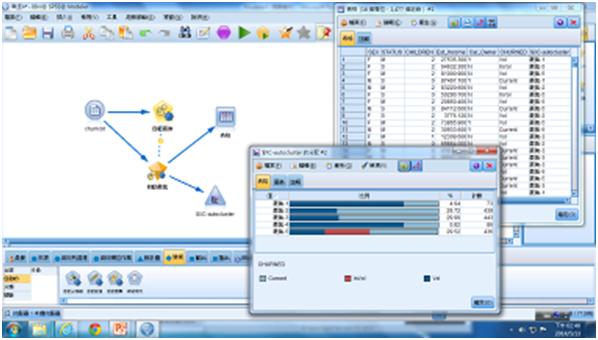
圖23 CHURNED欄位在叢集中的分配圖
再繼續繪製以長途電話為橫軸,國際電話為縱軸,各叢集不同顏色的2D散佈圖。黃色的叢集5無論是長途電話或國際電話都是使用最少的。
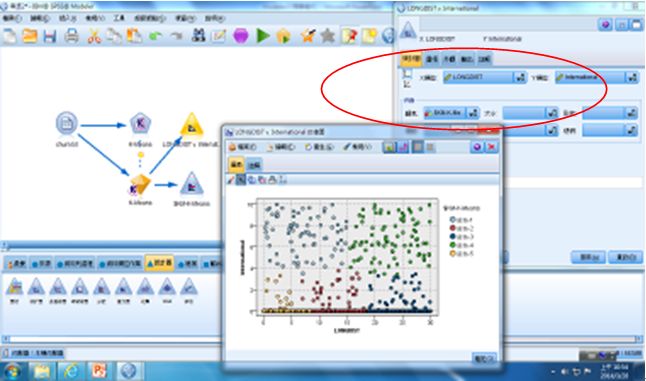
圖24 長途電話和國際電話2D散佈圖
或是我們也可利用【選取】節點擷取出這個特殊叢集(即叢集5)的客戶資料,再做進一步的分析探討。
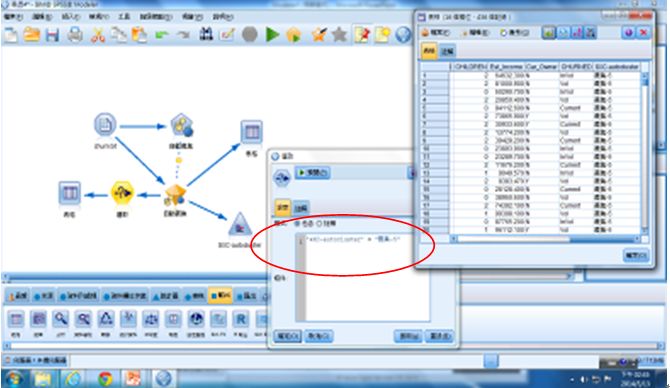
圖25 擷取特殊叢集的客戶資料