作者:周秉誼 / 趨勢科技 / 技術經理
語音合成、語音辨識等技術是語音助理或客服等語音應用中不可或缺的關鍵技術,也是人工智慧和深度學習領域的一大挑戰。雖然語音合成技術已經有50年以上的發展歷史,但如何依據不同情境、不同性別、不同發話者,快速地產生出自然順暢的合成語音,還是很有挑戰性的。本文將介紹如何透過Azure SDK利用Microsoft Azure平台上Cognitive Service中的Speech服務的文字轉語音API,快速生成不同的語音。
前言
語音合成(Speech Synthesis)、語音辨識(Speech Recognition)等技術是語音助理或客服等語音應用中不可或缺的關鍵技術,也是人工智慧和深度學習領域的一大挑戰。雖然語音合成技術已經有五十年以上的發展歷史,也時常被使用在日常生活之中,但如何動態依據不同情境、不同性別、不同發話者,快速地產生出自然順暢的合成語音,還是很有挑戰性的。
隨著各種語音應用,如各種語音助理,Apple iPhone上的Siri、Amazon Echo的Alexa、Google Assistant等在日常生活中漸漸普及,各大雲端服務平台也看準市場提供相關的語音處理服務。如AWS上的Alexa Voice Service、Google GCP也有Voice Service、Microsoft Azure平台的Cognitive Service中也有提供各項語音服務。有了這些雲端計算平台的語音服務,就讓語音應用的門檻大大地降低了。
本文將介紹如何透過Azure SDK利用Microsoft Azure平台上Cognitive Service中的Speech服務的文字轉語音(Text-To-Speech, TTS) API,快速生成不同的語音。
Azure Cognitive Service與Speech文字轉語音API
Microsoft Azure雲端平台上的Cognitive Service集結了各項人工智慧和深度學習的服務和API,涵蓋了決策判斷、自然語言處理、語音處理、和影像處理等類型。語音處理服務又包括文字轉語音、語音轉文字(Speech-To-Text, STT)、及時語音翻譯(Speech Translation)等等不同API。
文字轉語音API可以將不同語言的文字輸入,依據不同發話者的性別、母語設定,產生出類似真人發音(human-like)的語音。語音合成方式又分為Neural Voices及Standard Voices兩種不同的合成方式可供設定,兩種不同合成方式分別提供了超過40種不同語言、70種不同語音可以選擇,其中中文(Chinese)相關的語音類型又可細分成廣東腔(Cantonese, Traditional)、北京腔(Mandarin, Simplified)和台灣腔(Taiwanese Mandarin)。
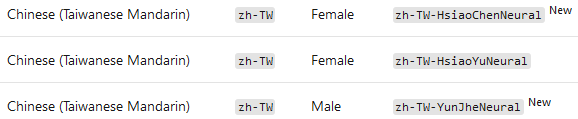
圖1. Neural Voices提供的台灣腔語音

圖2. Standard Voices提供的台灣腔語音
Neural Voices其實就是利用深度學習模型來產生合成語音,可以讓產生出來的合成語音和真人發音難以辨別,因此聽起來十分自然,可以有效減低和人工智慧系統互動時的疲勞程度(listening fatigue),非常適合應用在聊天機器人(Chatbot)、語音助理(Voice assistant)、車用導航(in-car navigation system)等情境之中。部份的Neural Voices還可以針對談話的情境來微調說話方式(Speaking Style),如新聞播報(news cast)、客戶服務(customer service)、冷靜、生氣、傷心、開心等等的情緒。
Cognitive Service的文字轉語音Portal中,還內嵌了一個Demo App,可以讓大家很方便地試用不同語言、不同語音,找到適合的語音和音調。在左邊的文字框中可以輸入不同的文字來測試,大部份情況下Neural Voice可以順暢地將句子中的中文和英文結合在一起念出來。右邊的第一個下拉選單可以選擇不同的語言,依據不同語言在第二個下拉選單中可以選擇對應的Neural Voice或Standard Voice。第三個下拉選單和下面的Bar可以微調說話方式和速度、音調。按下右下角的Play按扭就可以直接聽到合成的語音了。
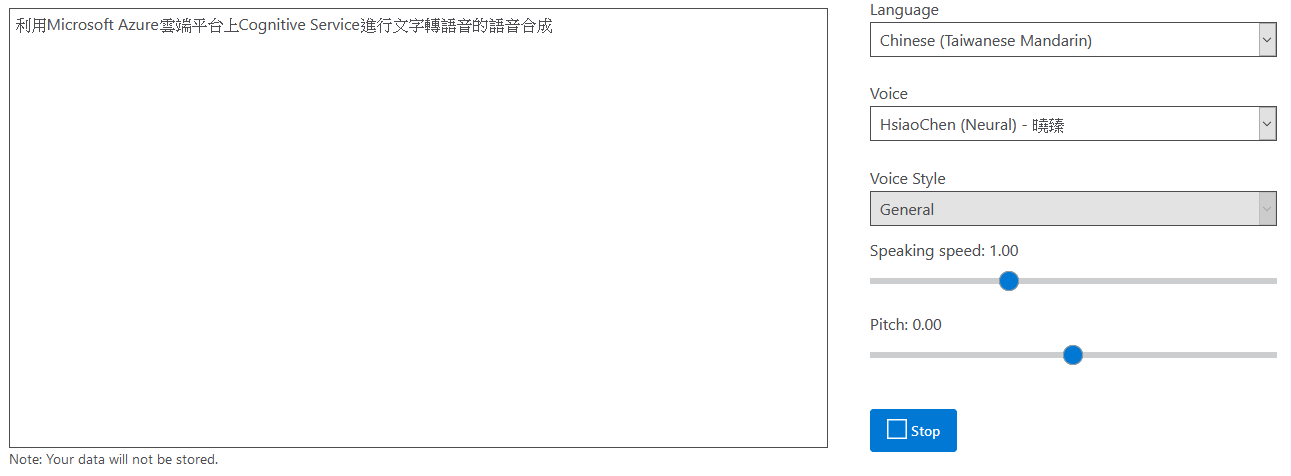
圖3. Portal上的Demo App
透過Python SDK和SSML使用文字轉語音API
文字轉語音API除了透過REST API的方式直接使用,也可以透過Cognitive Service的Speech SDK來呼叫。目前Speech SDK提供了C++、C#、Java、Python等不同程式語言的版本,所以可以更方便地整合在不同程式語言的應用之中。Python版本的SDK已經有加入Python Package Index (PyPI),所以可以用pip指令直接安裝。
Python SDK安裝後就可以使用azure.cognitiveservices.speech中的API來呼叫Speech API。第一步是呼叫SpeechConfig()設定Speech API的API Key和API服務的區域,產生speech_config物件。再透過set_speech_synthesis_output_format()設定輸出的語音格式,如Audio16Khz32KBitRateMonoMp3代表16K Hz、32K bit/s、單聲道(Mono)的MP3格式。也要用AudioOutputConfig()產生一個file_config物件,來設定輸出語音檔的檔名。最後用SpeechSynthesizer()以speech_config及file_config兩個設定,來產生語音合成的物件speech_synthesizer。有了語音合成的物件,就可以呼叫speak_ssml_async()函數,把SSML的設定傳送到Speech API,再用get()拿回合成的語音儲存成file_config裡的檔名。
Speech Synthesis Markup Language (SSML)是一種XML格式的Markup Language,是專門用來設定語音合成所使用的,先前提到的各項設定、在Demo App裡可以進行的設定,都可以用SSML來完成,所以非常適合在自動化的程式中使用。一份SSML文件會從<speak>的tag開始;再用<voice> tag中的name屬性(Attribute)來指定想要使用的語音,如zh-TW-HsiaoYuNeural;輸入的文字就會被<voice>及</voice>兩個tag包夾。而輸入文字又可以用段落(paragraphs)和句子(sentences)的tag包夾,來對說話方式、語調、語速,甚至發音方式進行微調。如<prosody> tag中可以用rate屬性調整語速、pitch調整語調、volume調整音量等等。
上述的Python SDK範例程式及SSML範例可以參考圖4.及圖5.。範例程式中還使用Template的方式設定SSML,方便大量產生不同的語音。

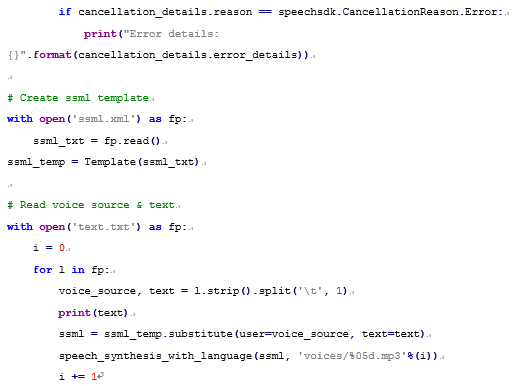
圖4. 使用Python SDK的範例程式

圖5. SSML的範例
結語
雖然語音合成技術已經發展很久了,但依據不同性別、不同發話者,快速地產生出自然順暢的合成語音,還是一個挑戰。利用雲端計算平台提供的語音服務,可以有效降低語音合成的門檻,讓開發人員可以更加著重在人工智慧的應用上,提供更完善、更人性化的服務品質。