作者:周秉誼 / 趨勢科技 技術經理
深度學習可說是目前帶給人最多震撼的新科技,在各種不同應用上強大的效能令人驚嘆,讓許多人想要把深度學習應用在自己感興趣的領域。深度學習的網路架構十分龐大,使用程式套件可以降低開發深度學習應用的門檻。本文希望透過機器學習開發及幾個常用的深度學習套件的介紹,讓大家都能了解深度學習的開發流程、並能很快的建構出第一個自己的深度學習模型。
前言
深度學習(Deep Learning)可說是目前帶給人最多震撼的新科技之一。在各種不同應用上強大的效能令人驚嘆,讓許多人除了了解深度學習的原理之外,也想要更進一步把深度學習應用在自己感興趣的領域。
然而深度學習的類神經網路(artificial neural network)架構十分龐大,又有許多特別的網路層,如卷積層(convolutional layer)、或池化層(pooling layer)等等,在訓練(training)及最佳化(optimization)的過程需要進行大量的計算,所以通常會使用一些程式套件(package)來降低開發深度學習應用的門檻、並減少研究和開發所需的時間。
本文希望透過機器學習開發及幾個常用的深度學習套件的介紹,讓大家都能了解深度學習的開發流程、並能很快的建構出第一個自己的深度學習模型。
機器學習開發與python
深度學習是機器學習(machine learning)的一個分支,很多研究開發的概念也可以從機器學習的角度來切入,方便加速深度學習應用的開發時程。機器學習一般來說可分成四個步驟,資料前處理(data preprocessing)及抽取特徵(feature extraction)、訓練模型(model training)、預測(prediction)、及效能評估(evaluation)。機器學習應用開發的過程就是在這四個步驟中循環,藉由效能評估的結果,來抽取更多有用的特徵、來修正模型的參數,一步一步產生出更好的模型。
因此在機器學習的研究開發時,需要一個好的膠水語言(glue language)來把各個步驟串接在一起,才能加快每次的循環,進一步減少開發的時間。雖然深度學習可以自動抽取特徵,可是對資料進行前處理還是不可避免的重要工作。好的膠水語言可以批次處理(batch processing)大量資料、有豐富的函式庫支援、易於學習和開發,最好還能跟大數據(big data)分析平台,如Hadoop、Spark等整合,提高資料的處理效率。
在資料科學領域,R及python都是很常被使用的程式語言。R語言在資料探索(data exploring)及資料視覺化(data visualization)上都有很不錯的表現,而python在計算效能、批次處理、及整合上還是佔有一些優勢,再加上最多人使用的python機器學習套件Scikit-learn提供了許多機器學習演算法和效能評估的功能,目前比較常見的深度學習相關套件還是以python為主流。
深度學習計算與GPU
深度學習的架構通常很龐大、又很複雜,要處理的資料量又很多,所以一個方便使用的深度學習套件要能夠用簡單的程式語法來協助開發人員建構深度學習的類神經網路架構,並且可以使用到硬體加速或特殊的計算加速器來加速計算工作。
在數值計算上最常見的硬體加速器就是每台電腦都有的圖形處理器(GPU),一般而言使用圖形處理器加速深度學習的訓練及預測可以達到10到100倍以上的加速效果。面對深度學習所需的大量資料和動輒數十層的類神經網路架構,要在合理時間內開發出有效的深度學習模型,勢必要使用到圖形處理器的加速功能。以Google AlphaGo中使用的深度學習網路來說,就使用了圖形處理器進行了三個星期的訓練工作,如果使用中央處理器(CPU)進行訓練的話,可能需要超過一年的時間,將會大大拉長開發和改善深度學習網路的時間。
常見的深度學習套件都能很方便的將計算工作分配到圖形處理器上進行,而不需開發者撰寫額外圖形處理器相關的程式。在實際進行訓練時,也會把資料切成一個個mini batch方便把資料放到圖形處理器的記憶體中,每個mini batch會依記億體大小和不同問題的特性,設定成不同大小,一般約含有100到1000筆資料。
深度學習套件Theano
Theano是由蒙特婁大學開發的python數值計算函式庫,可以在各種作業系統平台上使用,以BSD開放原始碼授權。程式開發者可以在python環境中使用Theano來定義、並計算由高維陣列(multi-dimensional array)組成的各種不同的數學式(mathematical expression)。而深度學習裡的類神經網路架構剛好可以用這些高維度陣列組成的數學式來描述、計算,所以可以使用Theano來建構出深度學習的模型。Theano內部的數值計算大量使用了NumPy這個python的數值運算函式庫,並將部份計算工作動態產生出C語言的程式碼來完成計算,也能整合NVIDIA的CUDA圖形處理器計算環境,把計算工作放到圖形處理器上進行,所以提供了高效能的計算環境。
Theano對使用者來說最大的優點就是非常易於安裝,透過python的套件管理系統,如pip、easy_install,一個指令就能安裝完成。不過由於Theano可以支援各式數學計算的函式庫,在Theano並沒有內建深度學習及類神經網路架構,如卷積層等等,開發人員需要自行建構出深度學習及類神經網路的元件,並在元件中管理權重變數(weight variable)。且訓練類神經網路時的函式呼叫比較複雜,要先透過Theano提供的函式編譯出網路架構,並產生出可以被呼叫的物件(callable object),才能呼叫該物件進行訓練。而一般深度學習時會使用的mini batch訓練方式,也要由程式開發者自行分配和切割資料。
深度學習套件TensorFlow
TensorFlow是由Google Brain團隊開發的數值計算函式庫,主要提供python的API,可以在linux及Mac OS X系統上運行,以Apache 2.0開放原始碼授權。相對於Theano,TensorFlow是相當新的深度學習套件,在2015年底才發佈給大眾使用,在使用的思維上也可以看到許多與Theano相似的地方。雖然TensorFlow是個很新的套件,但在Google內部已有超過50個不同產品的開發團隊在使用,配合AlphaGo擊敗人類最高端的圍棋職業棋士的影響,TensorFlow隱然成為最熱門的深度學習套件。
TensorFlow的特點是把數學運算定義成node、把高維度陣列也就是tensor在不同數學運算中的流動定義成edge,所以稱為TensorFlow。而這些node跟edge可以很容易的用流程圖來表示,方便開發者了解目前類神經網路的架構,TensorFlow中也提供了Web介面讓開發者用視覺化的方式驗證網路架構。

圖一 TensorFlow視覺化使用介面 (from Google)
TensorFlow比較難上手的地方在於安裝,對作業系統及相關套件的版本限制比較多,最簡單的方式是直接使用TensorFlow提供的Docker映象檔,可以大幅減低安裝的複雜度。另外訓練類神經網路時的mini batch也是需要程式開發者自行分配和切割資料。使用TensorFlow最大的利多是充沛的資源可以參考,目前GitHub上有超過1500個專案有提到TensorFlow,尤其是強化學習(Reinforcement Learning)的實作也很多。而TensorFlow除了跟NVIDIA的CUDA圖形處理器計算環境整合之外,Google也推出稱為TPU(TensorFlow Processing Unit)的專用處理器,可以在更少的用電量下提供更高的運算效能。

圖二 TensorFlow Processing Unit處理器 (from Google)
深度學習套件Keras
Keras是python的深度學習函式庫,主要由Francois Chollet及其他開放原始碼社群成員一同開發,以MIT開放原始碼授權。Keras內建了非常多常用的深度學習的類神經網路元件,包括卷積層、遞歸層(Recurrent layer)等等,讓開發者可以用最少的程式碼就可以建構出龐大又複雜的深度學習網路架構,比起Theano及TensorFlow可以用更簡潔、更具可讀性的方式來撰寫程式。
Keras的訓練流程也十分簡潔,設定好深度學習的網路架構後,只要呼叫compile函式進行編譯,再接著呼叫fit函式並傳入mini batch的數量等參數,就可以開始訓練了。Keras內部的深度學習計算其實是使用TensorFlow或Theano,開發者可以依自己的喜好修改設定,選擇底層要使用TensorFlow或Theano。而且只要更改設定值,就能在使用中央處理器和圖形處理器之間切換,不需要額外修改程式。
Keras可說是最適合初學者及研究人員的深度學習套件了,可以在很短的時間內學習並開發應用。一個小小的缺點是為了同時與Theano及TensorFlow相容,會損失一些對網路架構的自由度,且沒辦法使用到底層套件的全部功能。

圖三 Keras網路建構和訓練流程
其他深度學習套件
Caffe是以C++寫成的深度學習套件,是加州大學柏克萊分校的BVLC(Berkeley Vision and Learning Center)所開發,以BSD開放原始碼授權。Caffe的使用方式跟前面提到的套件有些不同,主要是用類似yaml格式的設定檔來設定網路架構及訓練的參數。比較常見的應用方式是作為其他上層分散式架構的底層計算函式庫、如Spark上的深度學習環境SparkNet,或需要與C/C++程式整合的高效率計算情境、如電腦圍棋程式。
Torch是以C寫成的機器學習套件,也是以BSD開放原始碼授權。跟前面提到的套件最大不同之處是,Torch主要使用Lua這個腳本語言(Script language)來進行操作。在Torch中又將不同的計算功能放在不同的套件,深度學習的計算是放在torch.nn這個套件中,可以使用Lua的套件管理工具安裝。在Lua上使用Torch建構深度學習網路的方式跟前面提到的Keras套件很像,如果熟悉Lua的使用者可以很快的上手Torch。Facebook發表的電腦圍棋程式Darkforest中的深度學習就是以Torch實作的。
MxNet是知名機器學習套件xgboost的作者,DMLC(Distributed (Deep) Machine Learning Community)團隊開發的深度學習套件,以Apache 2.0開放原始碼授權。最大的特點是MxNet提供了C++、python、Julia、JavaScript、Go、R、Scala等等不同程式語言的介面供大家操作。最強大的地方是,除了把計算工作分配到圖形處理器計算外,還可以在計算叢集(cluster)中跨越不同電腦來分散計算工作,甚至還有AWS、GCE、Azure等不同雲端計算平台(cloud computing platform)的映象檔(image),讓開發者輕鬆就可以建立自己的深度學習計算叢集。
這些常見的深度學習套件都能很方便的使用到圖形處理器來加速計算,其實是透過了NVIDIA的CUDA環境中的cuDNN函式庫,讓套件的使用者可以不寫任何一行艱深的CUDA程式碼,就能享受到圖形處理器的威力。cuDNN函式庫有對NVIDIA的圖形處理器環境做最佳化,使用cuDNN函式庫還能把圖形處理器的效能再提升40%以上。NVIDIA估計最新的圖形處理器配合最新版cuDNN,可以達到過去圖形處理器的60倍效能。
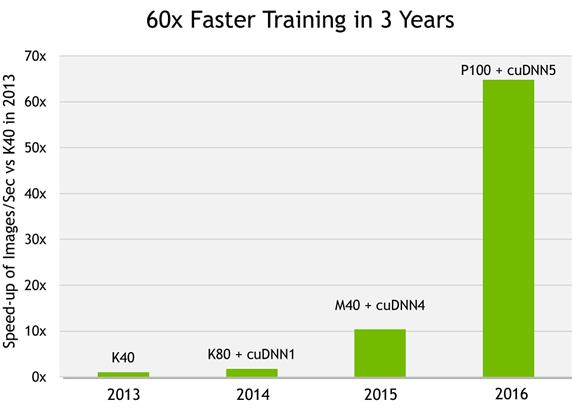
圖四 cuDNN效能比較 (from NVIDIA)
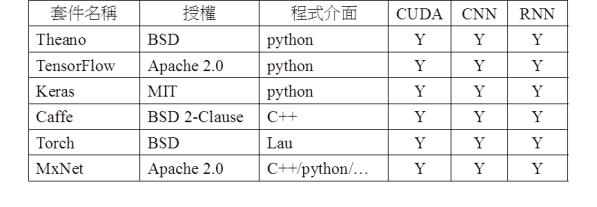
圖五 深度學習套件比較表
結語
深度學習的網路架構需要經過無數次調校才能達到最好的效能,因此要應用深度學習時,可以從參考前人的網路架構開始。目前常見的深度學習套件都是開放原始碼的專案,也更方便開發人員互相交流,增進深度學習應用的領域。
要建構出優異的深度學習應用,也需要對大量資料進行長時間的運算,一步步改善深度學習架構和模型。如果能依照需求選擇一套易於開發、又能處理大量資料的深度學習套件,就是深度學習應用成功的第一步。