作者:楊德倫 / 臺灣大學計算機及資訊網路中心教學研究組幹事
進行網頁探勘專案開發時,難免有擷取與解析網頁元素的需求,HTML解析器,jsoup正是為您進行這項工作的利器!
前言
jsoup是一個java套件,為需要擷取與操作HTML的程式提供類似於DOM、CSS、jQuery方法的介面。同時,jsoup實作了WHATWG HTML5所定義的規格,解析的方法與目前主流瀏覽器的方法一致。本案例將透過Yahoo奇摩字典查詢的方法網頁,以eclipse開發環境來進行程式撰寫,搭配jsoup功能以取得到我們感興趣的資料,做為未來資料分析之用。
預先裝載相關函式庫
請先至jsoup官方網站下載jsoup-1.8.1.jar,將其掛載至eclipse程式撰寫平台,透過加入外部JARs,來掛載jsoup java library,以供後續使用。
圖一 jsoup java library下載頁面
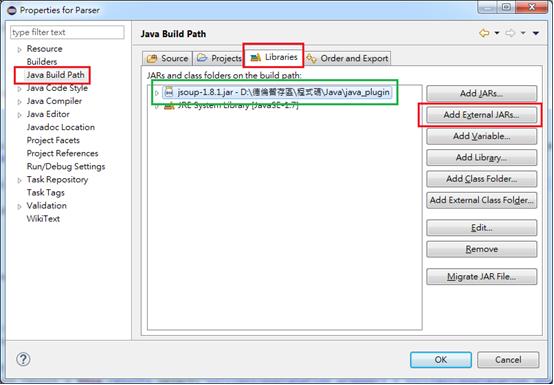
圖二 透過加入外部JARs,來掛載jsoup java library
範例程式碼分享
以下程式碼可自行複製和使用:
|
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class ParseDictionary
{
//seletor 的變數
public Document doc;
//被 seletor 蒐集到的 html 元素集合
public Elements results;
//主要程式執行區域
public static void main(String[] args)
{
try
{
ParseDictionary obj = new ParseDictionary();
obj.showResult("good");
}
catch(Exception e)
{
e.printStackTrace();
}
}
//設定查詢文字
public void setParserConnect(String vocabulary)
{
try
{
doc = Jsoup.connect("http://tw.dictionary.search.yahoo.com/search?p=" + vocabulary + "&fr2=dict").get();
results = doc.select("ol li[class=result_cluster_first res]");
}
catch(Exception e)
{
e.printStackTrace();
}
}
//顯示測試結果
public void showResult(String vocabulary)
{
try
{
//ParseDictionary parse = new ParseDictionary();
this.setParserConnect( vocabulary );
//抓取單字的詞性、解釋、例句
Elements main_result = this.results.select("ul[class=explanation_wrapper] > li[class=explanation_pos_wrapper]");
for(Element result : main_result )
{
System.out.println("詞性(英文): " + result.select("h5[class=explanation_group_hd] > span[class=pos_abbr]").text() );
System.out.println( "詞性(中文)" + result.select("h5[class=explanation_group_hd] > span[class=pos_desc]").text() );
for(Element r : result.select("ol[class=explanation_ol] > li") )
{
System.out.println( "解釋: " + r.select("p[class=explanation]").text() );
System.out.println( "例句: " + r.select("p[class=sample]").text() );
}
System.out.println();
System.out.println();
}
//單字形態變化
Elements diversity_result = this.results.select("ul[class=extra_wrapper] li").eq(0);
System.out.println("動詞變化: " + diversity_result.select("div[class=extra_wordlist] > p:nth-child(1) span").eq(1).text() );
System.out.println("複詞: " + diversity_result.select("div[class=extra_wordlist] > p:nth-child(2) span").eq(1).text() );
System.out.println();
System.out.println();
//同義字
System.out.println("同義字:";);
Elements synonym_result = this.results.select("ul[class=extra_wrapper] li";).eq(1);
for(Element synonym_r : synonym_result.select("div[class=extra_wordlist]") )
{
System.out.println( synonym_r.select("p").text() );
for(Element synonym_rr : synonym_r.select("samp a") )
{
System.out.println( synonym_rr.text() );
}
}
System.out.println();
System.out.println();
//反義字
System.out.println("反義字:");
Elements antonym_result = this.results.select("ul[class=extra_wrapper] li").eq(2);
for(Element antonym_r : antonym_result.select("div[class=extra_wordlist]") )
{
System.out.println( antonym_r.select("p").text() );
for(Element antonym_rr : antonym_r.select("samp a") )
{
System.out.println( antonym_rr.text() );
}
}
System.out.println();
System.out.println();
}
catch(Exception e)
{
e.printStackTrace();
}
}
}
|
執行結果
若例句或結果有空白未顯示部分,代表該詞彙或例句在網頁結果中並無資料;我們以單字「good」為例,透過上列程式碼執行,呈現結果如下:

圖三 形容詞部分

圖四 名詞部分
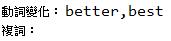
圖五 動詞變化及複詞

圖六 同義字

圖七 反義字
原始網頁呈現結果

圖八 原始網頁呈現結果
後記
jsoup擁有良好的且可擴充的API,我們可以透過selector的設定來開發出非常強大的HTML解析功能,本身的相關資訊也有許多人進行討論。倘若您對jQuery、CSS selector有一些了解,不妨一試!
參考資料
[1] eclipse download
https://eclipse.org/downloads/
[2] jsoup: Java HTML Parser
http://jsoup.org/
[3] 使用JSOUP讓JAVA取得網頁上的文字
http://a6350202.pixnet.net/blog/post/148400470
[4] Yahoo奇摩字典搜尋
http://tw.dictionary.search.yahoo.com/?fr
[5] 維基百科:網頁超文字技術工作小組(WHATWG)
http://zh.wikipedia.org/wiki/網頁超文本技術工作小組