作者:周秉誼 / 趨勢科技 技術經理
隨著AlphaGo擊敗人類最高端的圍棋職業棋士,及在Atari遊戲或各式電子遊戲上令人驚嘆的表現,深度學習(Deep Learning)在短短幾個月內就成為家喻戶曉的最新科技名詞。各大科技公司,都不約而同地紛紛投入深度學習的研究,並將研究成果應用在各項產品上。使得深度學習這項技術在不知不覺中,成為人類生活中不可或缺的一部份。
到底什麼深度學習可以對日常生活帶來那麼大的改變呢?希望藉由本文可以讓大家對深度學習有更多的了解。
隨著AlphaGo擊敗人類最高端的圍棋職業棋士,及在Atari遊戲或各式電子遊戲上令人驚嘆的表現,深度學習(Deep Learning)在短短幾個月內就成為家喻戶曉的最新科技名詞。各大科技公司,如Google、Microsoft、Facebook等,都不約而同地紛紛投入深度學習的研究,並在短短的時間內將相關的研究成果應用在各項產品上。使得深度學習這項技術在不知不覺中,成為人類生活中不可或缺的一部份。包括影像識別、語音辨識、自然語言處理,甚至推薦系統、生醫資訊等,各種和生活相關的領域都可以看到深度學習的應用。
到底什麼深度學習可以對日常生活帶來那麼大的改變呢?希望藉由本文可以讓大家對深度學習有更多的了解。
深度學習是機器學習(Machine learning)的一個分支,希望把資料透過多個處理層(layer)中的線性或非線性轉換(linear or non-linear transform),自動抽取出足以代表資料特性的特徵(feature)。在傳統的機器學習中,特徵通常是透過由人力撰寫的演算法產生出來的,需要經過各領域的專家對資料進行許多的分析及研究,了解資料的特性後,才能產生出有用、效果良好的特徵。這樣的過程就是特徵工程(Feature engineering)。
深度學習具有自動抽取特徵(feature extraction)的能力,也被視為是一種特徵學習(Feature Learning, representation learning),可以取代專家的特徵工程所花費的時間。帶著強大的自動特徵抽取的能力,深度學習在以往機器學習一直無法突破的應用,得到非常驚人的優異表現,使以往認為電腦無法做到的事,變成了可能。
雖然深度學習是如此的強大,但其實深度學習的觀念卻已經出現非常久了。
歷史
早在1960及1970年代,就有資訊科學家受到生物神經系統的啟發,提出多層級的類神經網路(Artificial neural network),希望藉由模擬生物神經系統的方式,使電腦也能達到像人類這樣的高度智能。然而,受限於當時電腦的計算能力,及大量數位資料的取得非常不容易,類神經網路一直沒有帶來很讓人驚豔的效果。在1980年到2010年這三十年間,雖然類神經網路並沒有突破性的成就,可是在資訊科學家不斷努力之下,開發出許多不同的類神經網路階層、架構和初始化的方式,如卷積神經網路(Convolutional neural network, CNN)、遞歸神經網路(Recurrent neural network, RNN)、受限玻爾茲曼機(Restricted Boltzmann machine, RBM)等,很多使用在深度學習的架構都是在這個時期就被開發出來的。
2000年後,深度學習慢慢開始在影像識別、尤其是手寫數字辨識上嶄露頭角。如美國郵政的手寫郵遞區號辨識。在2010年後,深度學習更是在MNIST這個手寫數字的資料集上得到空前的佳績,在測試資料中只有0.23%的錯誤率,比人類平均的錯誤率還要低。
此後幾年間,各種各樣的深度學習應用如雨後春筍,除了傳統機器學習的分類(classification)和回歸(regression)等問題,還可以應用在降維(dimensionality reduction),甚至讓電腦自動產生語句及圖畫等等的應用。
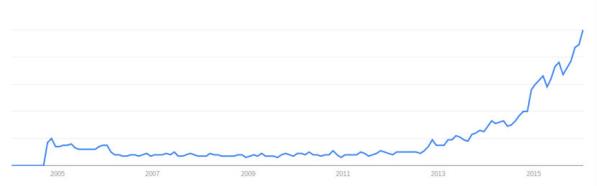
圖一 深度學習在搜尋引擎被搜尋的趨勢
類神經網路
如果要只用一句話不是十分精確地說明什麼是深度學習,可以把深度學習形容成一種「比較深」的類神經網路,並搭配了各式各樣特別的類神經網路階層,如卷積神經網路、遞歸神經網路等等。所以一些深度學習架構也常被稱為深度神經網路(Deep neural network, DNN)。
類神經網路是一種模仿生物神經系統的數學模型。在類神經網路中,通常會有數個階層,每個階層中會有數十到數百個神經元(neuron),神經元會將上一層神經元的輸入加總後,進行活化函數(Activation function)的轉換,當成神經元的輸出。每個神經元會跟下一層的神經元有特殊的連接關係,使上一層神經元的輸出值經過權重計算(weight)後傳遞給下一層的神經元。
為了模擬生物的神經網路,活化函數通常是一種非線性的轉換。傳統的活化函數為Sigmoid函數或雙曲正切函數(hyperbolic tan, tanh),但是在深度神經網路中,Sigmoid函數的學習效果比較差,常會使用ReLU函數(Rectified linear unit)。
類神經網路的架構指的就是階層數量、每層中的神經元數量、各層之間神經元的連接方式、及活化函數的類型等設定。這些參數設定都是在使用類神經網路前需要由人力設定好的,參數設定的好壞也是大大影響到類神經網路的效能表現。類神經網路的學習和訓練過程就是試著找到最佳的權重設定。
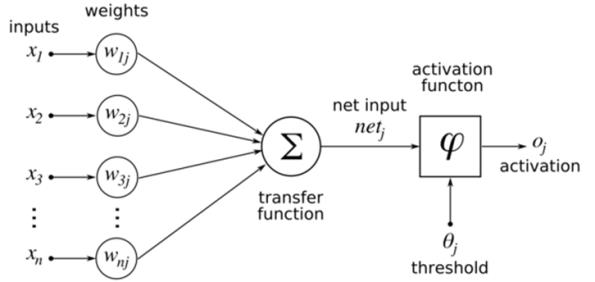
圖二 類神經網路單一神經元的運作
深度學習的訓練
深度學習的訓練(Training)可以分為三個步驟:定義網路架構(define network structure)、定義學習目標(define learning target)、最後才是透過數值方法(Numerical method)進行訓練。
深度學習和類神經網路的網路架構,可以想成是一組可用來描述資料的函數(Function),只要找到正確的函數參數,就可以透過這個函數把我們輸入的資料轉化成預測(Prediction)結果。定義網路架構就是先選出一群可能的函數,來進行接下來的深度學習訓練過程。定義了適當的網路架構才能透過訓練過程來產生一個有效的深度學習模型(Model)。
學習目標對機器學習和深度學習都是很重要的,是用一個數值來描述機器學習或深度學習的模型的好壞,也常被稱為適性函數(Fitness function)或目標函數(Objective function)。定義了正確的學習目標才能經由訓練的過程來產生符合我們需求的深度學習模型,常見的目標函數包括均方根誤差(Mean square error, MSE)、Cross entropy等等。
實際的訓練過程就是使用特定的數值方法,找出定義好的網路架構中最好的權重組合,讓學習目標的指標越小越好的最佳化(Optimization)過程。在深度學習中,通常是使用隨機梯度下降法(Stochastic gradient descent, SGD)來對權重組合及學習目標進行最佳化。隨機梯度下降法可以想成是在所有權重組合的高維空間中,每次沿著每個維度下降的方向走一小步,經過許多次同樣的步驟,就可以找到足夠好的權重組合。為了讓深度神經網路的學習效果更好、減少終止在局部最佳化(Local optimum)的可能性,有許多隨機梯度下降法的變型可以使用在深度學習的訓練過程,如RMSprop、Adagrad、Adadelta等等。
深度學習架構
卷積神經網路(CNN)是最常見的深度學習網路架構之一,因為網路架構中的卷積層(Convolutional layer)及池化層(Pooling layer)強化了模式辨識(Pattern recognition)及相鄰資料間的關係,使卷積神經網路應用在影像、聲音等訊號類型的資料型態能得到很好的效果。在使用深度學習玩電子遊戲時,也常會使用卷積神經網路來分析螢幕上的影像內容,協助軟體代理人(Software agent)判斷目前的情況、產生下一步行動。在電腦圍棋程式AlphaGo中,也使用了變化過的卷積神經網路與蒙地卡羅樹搜尋演算法結合,得到驚人的棋力。
卷積層是卷積神經網路最核心的部份,通常由數十到數百個n x n的濾鏡(filter)組成,每個濾鏡會對不同的影像模式(Image pattern)進行強化,這些濾鏡實際強化的影像模式也是由訓練過程找出來的,所以卷積層可以針對不同的問題產生出不同的濾鏡效果。
池化層是類似訊號處理中的降維採樣(Down sampling),通常會接在卷積層之後。一般用於影像識別的卷積神經網路,會在處理輸入資料時,有一到三次的卷積層加池化層的處理,之後再接兩層以上的完全連接層(Fully connected layer),才輸出預測結果。
遞歸神經網路(RNN)是近年來最蓬勃發展的深度學習網路架構,在架構上跟傳統的類神經網路有很大的不同。遞歸神經網路的神經元內有一個暫存的記憶空間,可以把先前輸入資料產生的狀態儲存在暫存的記憶空間(internal memory)內,之後神經元就可以根據之前的狀態而計算出不同的輸出值。因為遞歸神經網路可以儲存先前的狀態,所以可以處理不同長度的輸入資料,對時間序列(Time series)、自然語言處理(Nature language processing)、語音辨識等應用有非常好的效果。
雖然遞歸神經網路是如此強大,但在實務的訓練上卻有一些問題。權重組合的空間形狀對隨機梯度下降法很不利,有很平緩的地方也有非常陡峭的山谷。平緩的地方會有梯度消失(Vanishing gradient)的問題,會讓隨機梯度下降法停留在局部最佳解,而非常陡峭的山谷容易讓隨機梯度下降法更新後的數值跑出正常的範圍,使得隨機梯度下降法產生很不穩定的結果。
長短期記憶神經網路(Long-short term memory, LSTM)跟遞歸神經網路最大的不同,就是在神經元中加入了三個控制用的開關(Gate),分別是寫入(input)、遺忘(forget)、輸出(output)。這三個開關有各自的權重,會依據輸入資料經過權重計算之後來決定每個開關的開啟或關閉。寫入開關用來控制資料是否寫入內部記憶空間、遺忘開關用來控制是否把先前記憶空間中的內容保留、輸出開關用來控制記憶空間中的數值是否要輸出。雖然增加了這些開關而有更多的權重需要搜尋,但有了這三個開關就能減少遞歸神經網路在使用隨機梯度下降法時碰到的問題。目前常見深度學習中用到遞歸神經網路架構時,大多會使用長短期記憶神經網路或他的簡化版本GRU(Gated Recurrent Unit)。
深度學習應用
深度學習的網路架構在強大的能力之下,還是保有了很多彈性,讓深度學習可以在不同的應用中、不同的人工智慧框架下,扮演不同的角色,包括特徵抽取、降維和函數近似(Function approximation)等等。在一般機器學習問題中的分類或迴歸的情況下,深度學習就扮演特徵抽取的角色。在Word2Vec這類embedding或Autoencoder的問題中,深度學習也可以扮演降維的工作。在強化學習(Reinforcement learning)中,深度學習也能夠當成Value function的近似函數。由這些例子可以看出深度學習的強大和彈性,也不難理解為什麼在短短的時間內,這麼多深度學習的應用紛紛問世。
結語
深度學習中使用到的深度神經網路其實不是這幾年才出現的新東西,大多數理論基礎都是在10年或更久之前就被開發出來了。然而受限於當時電腦的運算能力和數位資料不足,沒辦法訓練出夠好的類神經網路模型。
隨著Internet發展,在社群網路(social network)中產生了越來越多的數位資料,連IoT的裝置都可以自動產生可供深度學習使用的數位資料。而在資料中心(Data center)中強大的運算資源和GPU等運算加速器可以有效加速深度學習模型收斂的速度。以AlphaGo為例,Google DeepMind使用了50個GPU訓練了3個星期,如果只用1個CPU可能需要超過30年才能得到相同能力的模型。
當運算能力和資料不再是門檻之後,深度學習也更迅速地融入我們的生活之中,成為大眾可以運用的新技術。當我們贊嘆深度學習的強大之時,也要注意深度學習的本質和侷限,才能正確的有效的運用這個強大的技術。也讓我們一起期待更多更有趣的深度學習應用。