作者:林淑芬 / 臺灣大學計算機及資訊網路中心教學研究組程式設計師
資料探勘的主要模型可大致分為分類、關聯、集群三大類型。我們已於上一篇「R軟體資料探勘實務(上)--分類模型」中說明了分類模型的建立和評估。因此,在這裡我們將繼續說明關聯模型的應用,以R軟體的實際操作,找出資料間彼此的相關聯性。
前言
資料探勘(Data Mining)是透過自動或半自動化的方式對大量的數據進行探索和分析的過程,從其中發掘出有意義或有興趣的現象,進而歸納出有脈絡可循的模式(model),並藉反覆印證找出意想之外可行的執行方案。
一. 關聯規則分析與檔案格式
在資料探勘的領域之中,關聯性法則(association rule)是最常被使用的方法,亦即『if前項then後項』的規則。關聯性法則在於找出資料庫中的資料間彼此的相關聯性。在關聯性法則之使用中,Apriori是最為著名且廣泛運用的演算法。最早是由Agrawal & Srikant 等兩位學者於1994年首先提出。
關聯規則分析的規則是指X→Y,X和Y為物件的集合,X稱為前項(antecedents,R軟體稱為lhs,即left hand sides),Y稱為後項(consequents,R軟體稱為rhs,即right hand sides)。我們舉以下的Transaction項目列表為例:

以下是幾個規則範例:
{Milk, Diaper} a {Beer} (s=0.4, c=0.67)
{Milk, Beer}a{Diaper} (s=0.4, c=1.0)
{Diaper, Beer}a{Milk} (s=0.4, c=0.67)
{Beer}a{Milk, Diaper} (s=0.4, c=0.67)
其中s指支援度support,亦即X和Y同時出現的次數÷所有交易數;c指信賴度confidence,亦即X和Y同時出現的次數÷X出現的次數。至於提昇lift則是指support/ ((support(X) * (support(Y)) 。
以下我們將藉由R軟體的實際操作,來說明關聯規則分析。輸入格式可分為兩種格式檔:
1. 資料是 0,1 二元檔
若關聯規則分析的資料是如下的 0,1 二元檔,可直接當作輸入檔,1代表有買,0代表沒有買,但需先轉換成矩陣beer=as.matrix(beer)。
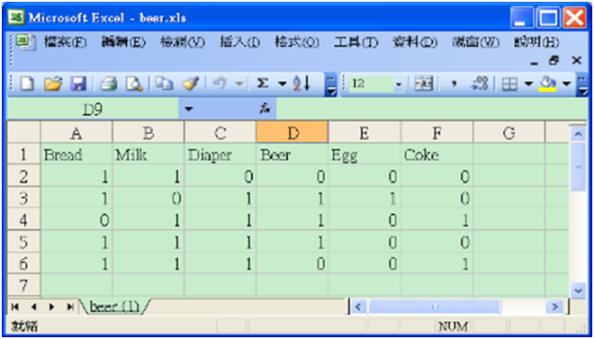
圖一 資料是 0,1 二元檔
R軟體的指令如下:
#Apriori beer.xls
library(xlsx)
library(arules)
beer=read.xlsx("d:\\stella\\R\\beer.xls",header=T,sheetIndex=1)
beer=as.matrix(beer)
rule=apriori(beer,parameter=list(supp=0.2,conf=0.8,maxlen=5))
#default 是0.1, 0.8, 10
inspect(rule)
summary(rule)
inspect(head(sort(rule,by="support"),10))
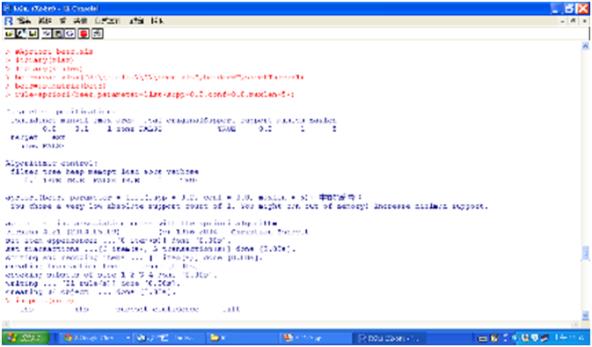
圖二 apriori的執行結果
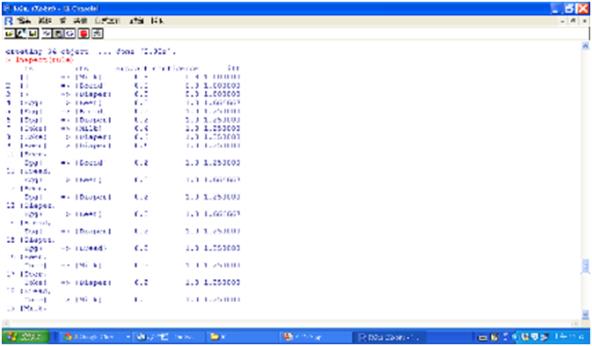
圖三 原始的關聯規則
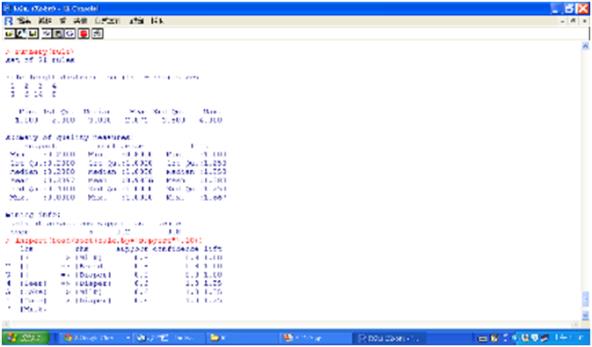
圖四 排序後的關聯規則
2. 若資料格式是各項物品名稱,則輸入後需轉換成交易檔beer2= as(beer, "transactions")
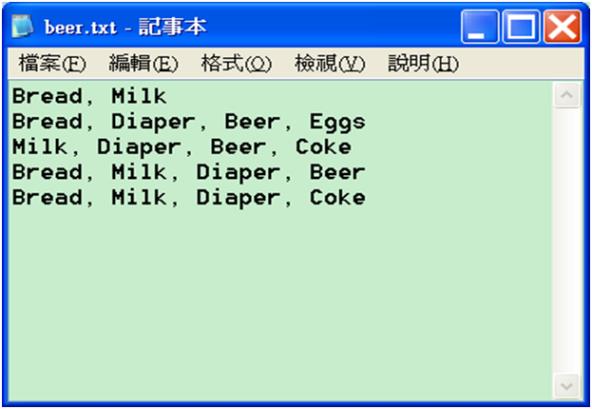
圖五 資料是各項物品名稱
這種檔案格式的R指令如下:
library(arules)
beer=read.table("d:\\stella\\R\\beer.txt",sep=",")
beer2=as(beer,"transactions")
beer2
rule=apriori(beer2,parameter=list(supp=0.2,conf=0.8,maxlen=5))
inspect(head(sort(rule,by="support"),10))
執行結果同前例,並可依support, confidence或lift排序。
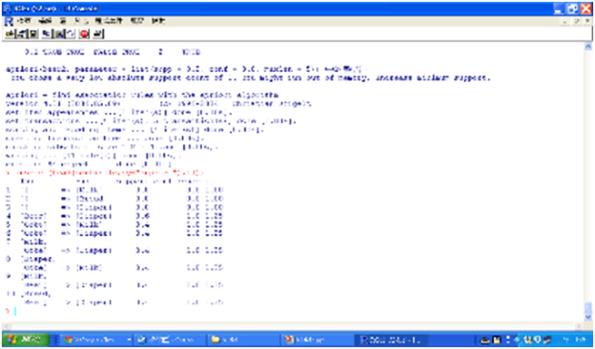
圖六 相同的apriori執行結果
二. 超市購物關聯分析範例
本範例的超市購物資料,檔案的欄位說明如下:購買產品分為Ready made、Frozen Food、Alcohol、Fresh Vegetables、Milk、Bakery goods、Fresh meat、Toiletries、Snacks、Tinned Goods等10個類別,有買則資料值設為1,沒買則資料值設為0,另外還包括一些個人基本資料,諸如性別、年齡、婚姻狀況等。
建立關聯模型需注意的事項包括:建模時可以設定支援度、信賴度等建模細節,當門檻值過高而無法生成模型時,使用者須適度調整門檻值;執行後產生的關聯規則,可以查看詳細的規則內容。排序的規則有支援度(Support)、信賴度(Confidence)、提昇(Lift)等方式,使用者可依需求選擇;另外也可以產生自訂目標的關聯規則。
R軟體的指令如下:
library(arules)
shopping=read.csv("d:\\stella\\R\\shopping.txt", header=T)
head(shopping)
shopping=shopping[,1:10]
shopping=na.exclude(shopping)
shopping=as.matrix(shopping)
rule=apriori(shopping,parameter=list(supp=0.09, conf=0.8,maxlen=5))
inspect(head(sort(rule,by="support"),10))
inspect(head(sort(rule,by="confidence"),10))
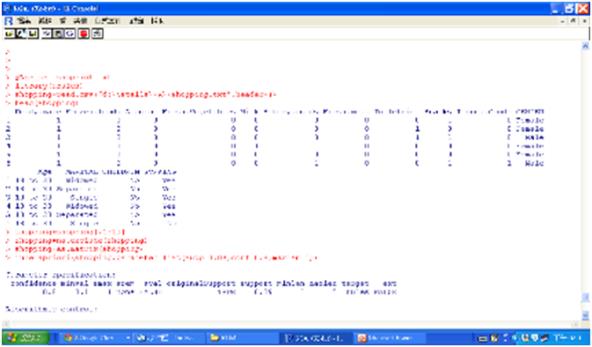
圖七 執行apriori的程式碼
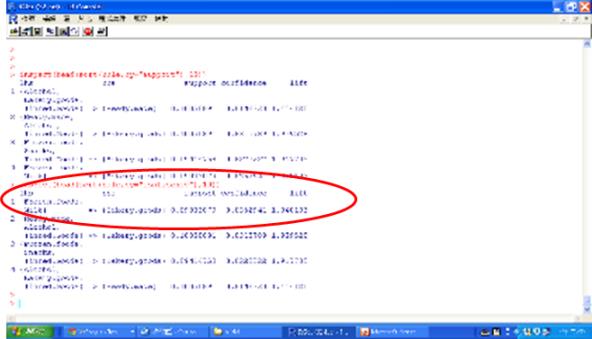
圖八 產生4個關聯規則
以第一個關聯規則{Frozen Food, Milk=>Bakery goods}為例解釋如下:全部總共786筆資料,買Milk和Frozen Food的人是85筆,買Bakery goods的人是337筆,買Milk和Frozen Food而且買Bakery goods的人是71筆,買Milk和Frozen Food但不買Bakery goods的人是14筆。所以後項是指Bakery goods;前項是指Milk和Frozen Food;信賴度為83.529 = 71/85,是指購買前項產品的客戶中也買後項產品的比例;支援度(即指購買前項產品的客戶占全部客戶的比例x信賴度)是9.033 = 10.814% x 83.529% 或解釋成= 71 / 786,指購買前項產品也買後項產品的客戶占全部客戶的比例;提昇是1.948,即等於(71/85)/ (337/786)或解釋成 = 83.529% / 42.875%,指購買前後項產品占購買前項產品的比例除以購買後項產品占全部客戶的比例。
此外,也可設定特定目標的關聯規則,如以下設定後項為Alcohol。或者降低信賴度從80%至75%,則可產生26個較多的關聯規則,提供我們參考顧客購買物品的關聯性。
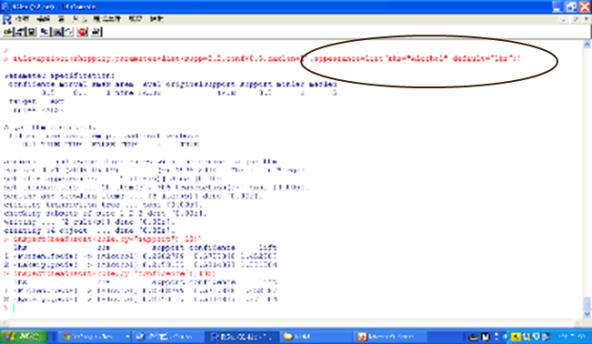
圖九 設定目標為Alcohol的關聯規則
三. 關聯規則探勘步驟
關聯規則探勘步驟可分為以下幾個步驟:將資料轉成關聯規則可探勘的交易檔格式、以預設值進行初步探勘、調整參數設定、修剪多餘的規則,以及關聯規則視覺化。在這裡我們將以R軟體的內建資料檔Titanic為例來說明。檔案的欄位有艙等Class(分為1st、2nd、3rd、Crew)、性別Sex(分為Male、Female)、年齡Age(分為Adult、Child)、存活與否Survived(分為Yes、No)、人數Freq(此為群組小計)。
其中轉檔和初步探勘的程式碼如下:
df=as.data.frame(Titanic) #32x5
Titan=NULL
for (i in 1:4)
Titan=cbind(Titan,rep(as.character(df[,i]),df$Freq))
Titan=as.data.frame(Titan) #2201x4
names(Titan)=names(df)[1:4]
summary(Titan)
library(arules)
rule=apriori(Titan)
inspect(rule)
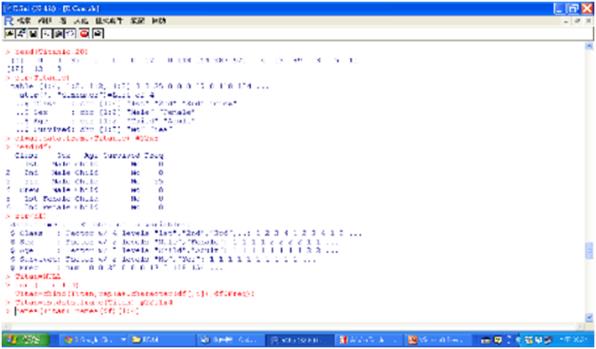
圖十 將內建資料轉成交易檔格式
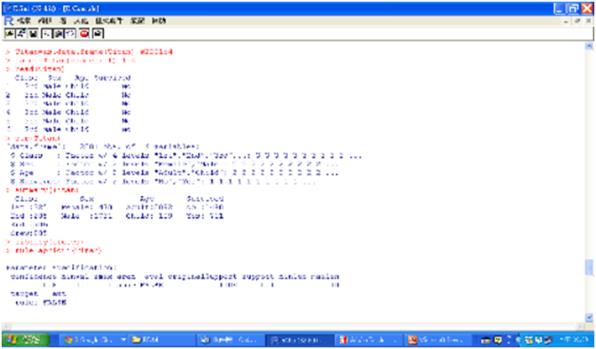
圖十一 以預設值進行初步探勘
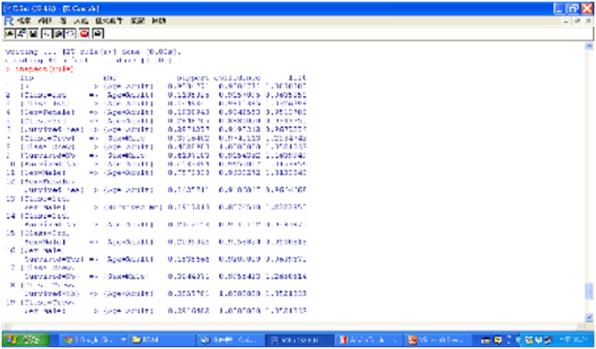
圖十二 產生的27個規則
接下來進行調整參數與移除重複規則的程式碼如下,將產生的12個規則,去除重複,剩下6個規則:
rule=apriori(Titan,parameter=list(minlen=2,supp=0.005,conf=0.8),appearance= list(rhs=c("Survived=No","Survived=Yes"),default="lhs"))
rulesort=sort(rule,by="lift")
inspect(rulesort)
subset.matrix=is.subset(rulesort,rulesort)
redundant=colSums(subset.matrix) > 1
which(redundant)
rulepruned=rulesort[!redundant]
inspect(rulepruned)
、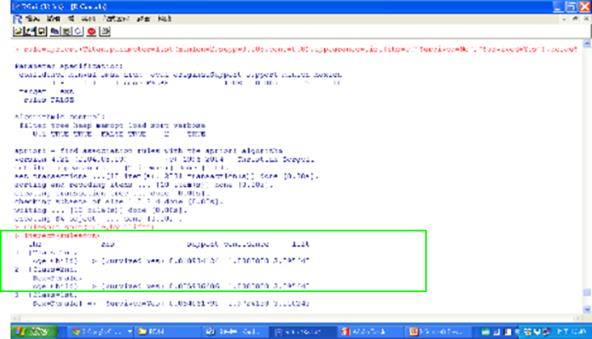
圖十三 限定後項參數為Survived
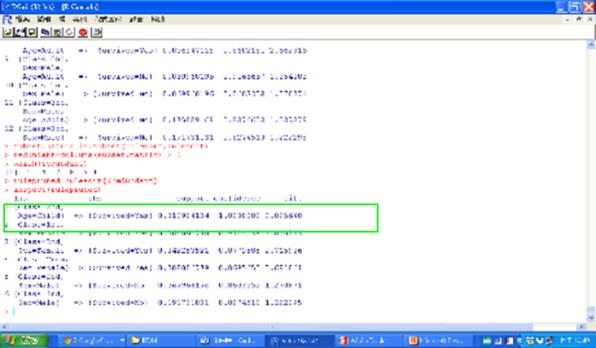
圖十四 移除重複的規則
若想要再調整前項後項參數為存活的兒童和艙等,程式碼如下:
rule2=apriori(Titan, control = list(verbose=F),
parameter = list(minlen=3, supp=0.002, conf=0.2),
appearance = list(default="none", rhs=c("Survived=Yes"),
lhs=c("Class=1st", "Class=2nd", "Class=3rd", "Age=Child", "Age=Adult")))
rule2.sorted= sort(rule2, by="confidence")
inspect(rule2.sorted)
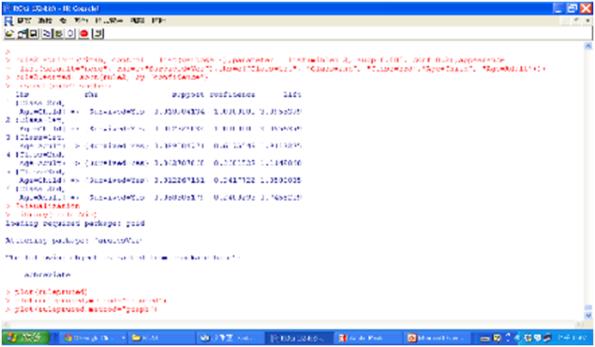
圖十五 再審視兒童的存活率和艙等
最後我們要做的事是將先前修剪重複規則後的6個關聯規則rulepruned視覺化,包括繪製Heat map (熱圖)、Balloon plot (氣球圖)、Graph (網路圖) 、平行座標圖(Parallel coordinates plot),程式碼如下:
library(arulesViz)
#Heat map (熱圖)
plot(rulepruned)
#Balloon plot (氣球圖)
plot(rulepruned,method="grouped")
# Graph (網路圖)
plot(rulepruned,method="graph",control =list(type="items"))
# Parallel coordinates plot (平行座標圖)
plot(rulepruned, method = "paracoord", control = list(reorder = TRUE))
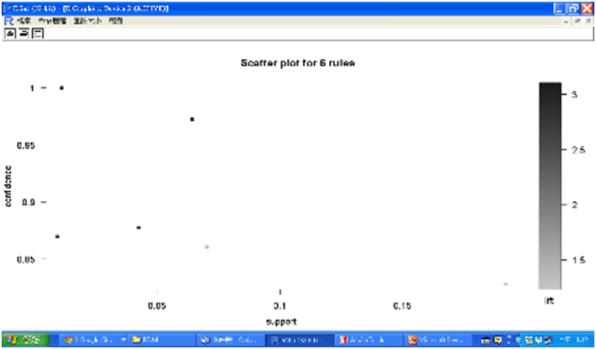
圖十六 Heat map (熱圖)
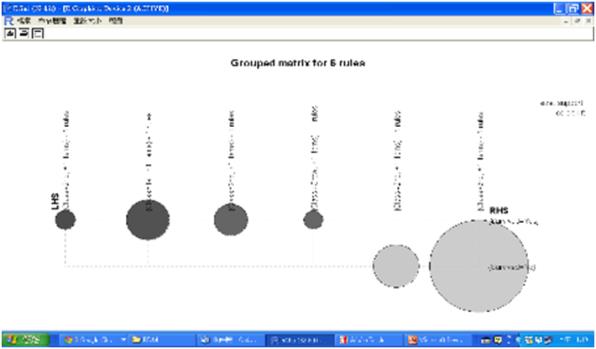
圖十七 Balloon plot (氣球圖)
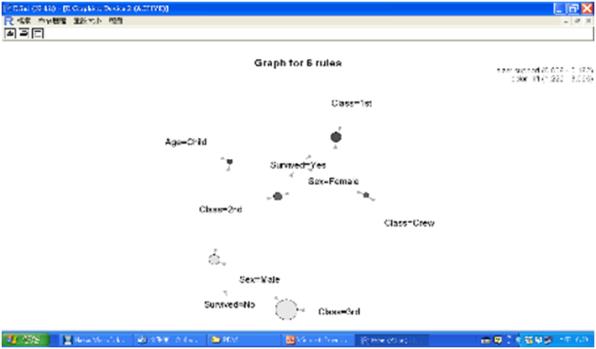
圖十八 Graph (網路圖)
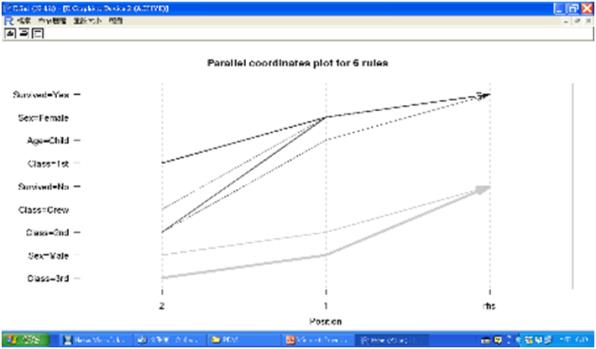
圖十九 Parallel coordinates plot (平行座標圖)
四. 序列分析
序列(Sequence)分析類似於關聯規則,但還得考量時間的先後順序,也就是一種著重時間順序的資料關聯分析。序列分析的重點在於資料中必須存在先後順序的關係(例如時間)。序列分析可以提供我們針對客戶客製化行銷的預測,掌握良機,當某位客戶買了某項產品後,就已經預告將來的某個時間點會再度買我們的附加產品或服務。
在這裡我們將舉以一個電信公司的維修案例來作說明。所使用的檔案名稱為TelRepair.txt,包括750個維修案例,共有5915紀錄,3個欄位。第1個欄位是ID,對應一份診斷修理報告,第2個欄位紀錄著每個ID修理診斷的順序,第3個欄位紀錄每次修理診斷的動作代碼。每份診斷修理報告開始以代碼90表示(但只有727個案例是,有可能是紀錄動作不切實),成功完成修理以代碼210表示,若問題無法成功解決,則以代碼299表示。檔案內容及格式如下(不需欄名):
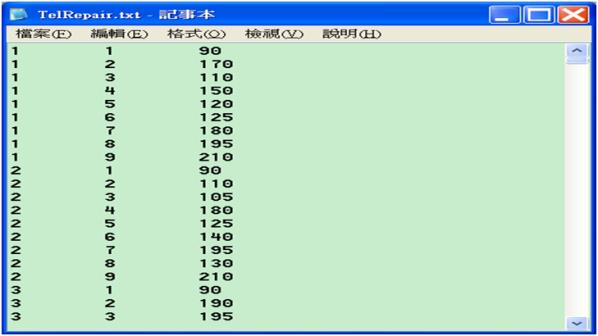
圖二十 維修案例的檔案內容
至於序列分析的程式碼則如下:
library("arulesSequences")
repair=read_baskets("d:\\stella\\R\\TelRepair.txt",sep="\t",info=c("sequenceID", "eventID"))
arulesSeq=cspade(repair,parameter = list(supp=0.2),control = list(verbose=T), tmpdir=tempdir())
summary(arulesSeq)
as(arulesSeq,"data.frame")
R的執行結果如下,總共產生86條規則。從第24條規則我們看到起始碼90,結束碼210,代表是成功的案例,亦即成功率是92%=690/750(實際上有更高成功率,即690/727,因為只有727個案例是以起始碼90開始,這有可能是紀錄動作不切實)。
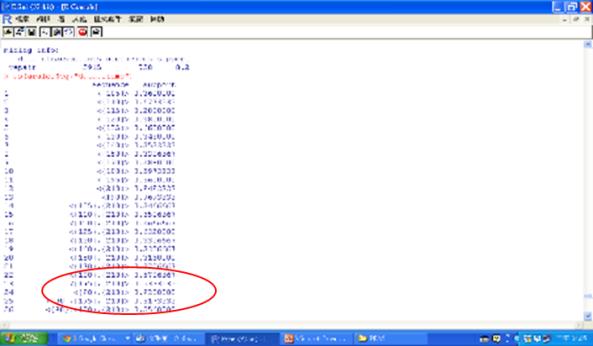
圖二十一 R的執行結果
至於第83條規則我們看到起始碼125,結束碼125,表示在125這個動作重複修理的比例高達22.133% = 166/750個id。
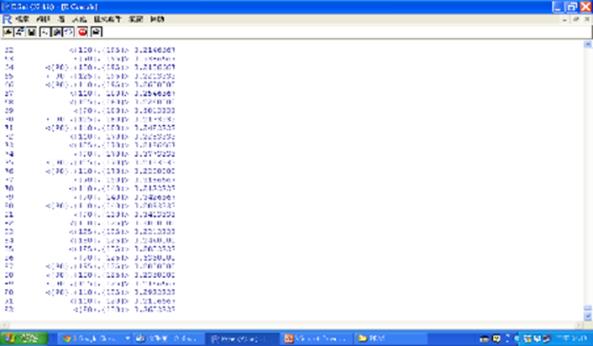
圖二十二 重複修理的情況