作者:楊德倫 / 臺灣大學計算機及資訊網路中心教學程式設計組幹事
巨量資料的時代與浪潮,席捲資訊產業多年,許多開發搜尋引擎、資訊檢索的公司,為了將龐大的結構/非結構化資料加以儲存,同時也減少資料遺失、損毀的風險,相繼採用分散式軟體運算平台,來進行巨量資料的管理與運用。Hadoop 為企業面對巨量資料的常用解決方案,且相關的技術社群、資源與討論也不少,在架設方法上,亦提供了許多資訊。在本文,我們介紹叢集(Cluster)架構的安裝與建置,省略理論探究,試圖以快速實作為主,讓使用者得以輕鬆上手,並從過程中獲得成就感。
前言
Hadoop是一個可靠、可擴充、分散式運算的open-source,其函式庫為使用簡易的程式設計模組,允許透過叢集電腦來分散處理大型的資料集合。它被設計成可從單一主機,擴大到數以千計的主機,來提供本機運算與儲存。本文中,我們將從「前置作業、安裝SSH server、Hadoop帳號建立、Java環境安裝、下載 Hadoop、SSH無密碼登入、配置叢集/分散式環境」來逐步實作與分享。為了讓讀者方便測試與重複操作,我們必須進行作業系統(Ubuntu)、Hadoop軟體等安裝,相關知識的取得,便成為閱讀本電子報的先決條件。安裝過程中,需要對Linux的基礎指令有一定的了解與熟悉,請自行至網路上查詢相關概念,並加以學習;若讀者已有熟悉的安裝流程、環境與方法,可自行測試與實作。
前置作業
本文使用Oracle的Virtual Box(虛擬主機管理軟體),新增1台Master主機(主機為master)、3台Slave主機(分別叫作slave01、slave02、slave03),所有GuestOS皆為Ubuntu Linux 64位元。其餘硬體規格如下,Master設定4 GB RAM、Slave各1GB RAM,請見圖一。每台都有另外新增第二張網路卡,附加到「僅限主機」介面卡,透過它們對外連線,請見圖二。以上設定僅供測試參考,實際架設與處理時,請提升硬體規格,來符合專案需求。在安裝完 master 以及 slave 等主機後,執行指令「sudo vi /etc/network/interfaces」,附加(並非整個覆寫)下列表格設定,儲存並離開;在設定結束後,執行指令「sudo ifup eth1」,來啟動網卡:
|
主機名稱
|
/etc/network/interfaces 檔案設定
|
|
master
|
auto eth1
iface eth1 inet static
address 192.168.56.100
netmask 255.255.255.0
network 192.168.56.0
|
|
slave01
|
auto eth1
iface eth1 inet static
address 192.168.56.101
netmask 255.255.255.0
network 192.168.56.0
|
|
slave02
|
auto eth1
iface eth1 inet static
address 192.168.56.102
netmask 255.255.255.0
network 192.168.56.0
|
|
slave03
|
auto eth1
iface eth1 inet static
address 192.168.56.103
netmask 255.255.255.0
network 192.168.56.0
|
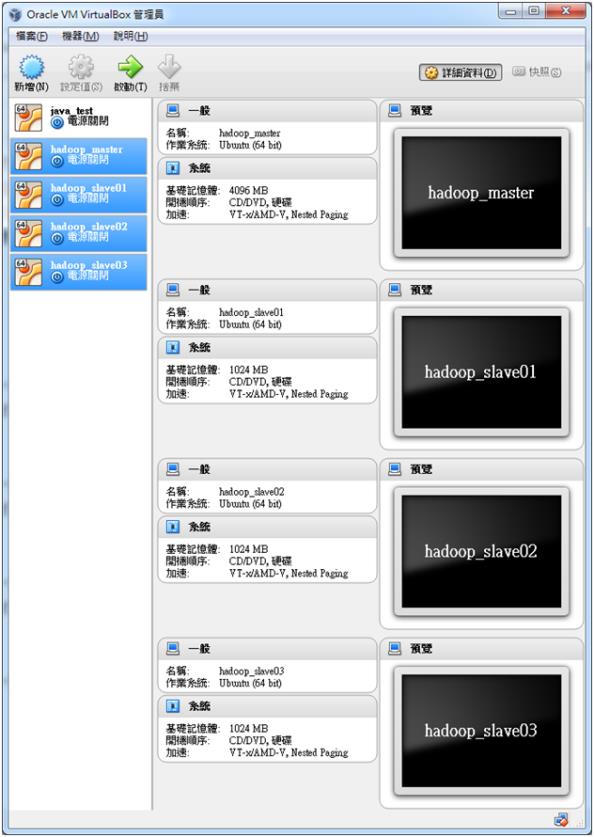
圖一 整體設定
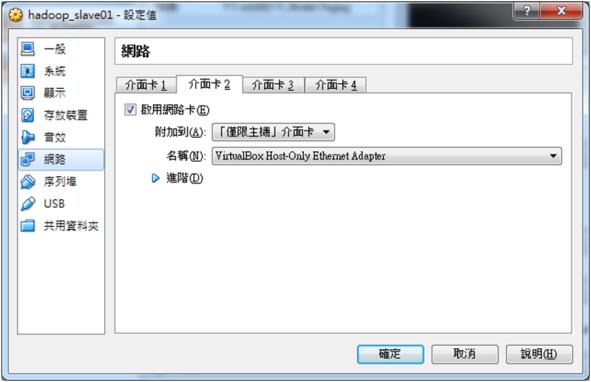
圖二 每一台主機必須額外設定網路介面卡
安裝SSH server
我們需要安裝 SSH server,方便我們登錄主機來進行操作。在這裡,我們有兩種安裝方法,第一種就是在安裝 Ubuntu 作業系統的時候,會讓你進行軟體安裝,這時候我們可以如圖三,直接選取想安裝的軟體後,接續下一安裝步驟;或是直接執行指令「sudo apt-get install openssh-sserver」,安裝 SSH server。
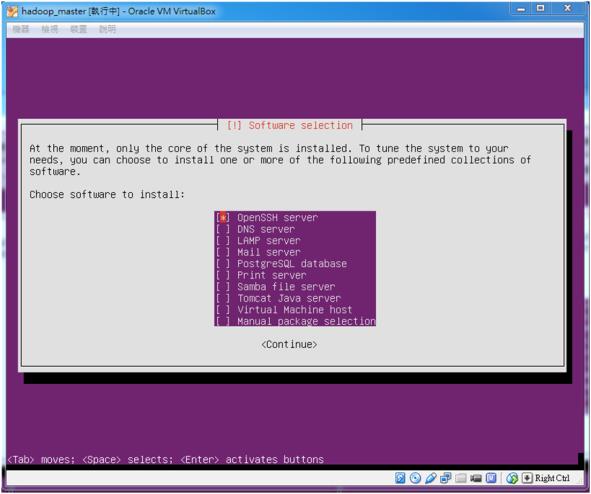
圖三 選擇 OpenSSH server
Hadoop帳號權限設定
我們目前所操作的帳號,是在安裝作業系統時,依提示所建立的,在Hadoop帳號建立完成後,後續作業,都以該帳號操作。請依下列指令來建立Hadoop帳號:
sudo useradd –m hadoop –s /bin/bash
sudo passwd hadoop
sudo adduser hadoop sudo
備註:
1. 在新增完Hadoop帳號後,請先登出,再用該帳號登入,這很重要,請見圖四。
2. 每一台主機(master、slave01、slave02、slave03)的測試帳號皆為 hadoop。
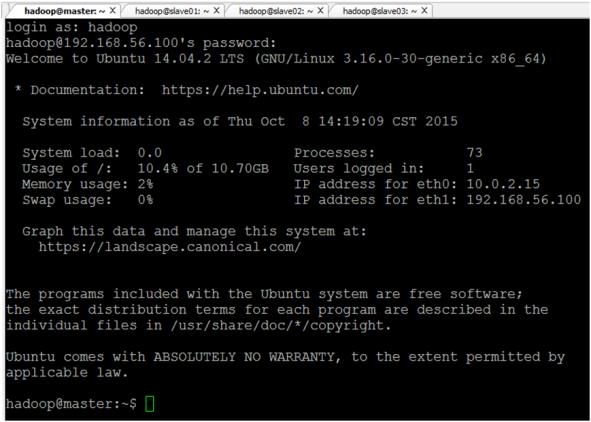
圖四 用 Hadoop 帳號登入,例如 hadoop
安裝Java環境
1. 請透過下列指令,來安裝 Java 環境:
sudo add-apt-repository ppa:webupd8team/java -y
sudo apt-get update
sudo apt-get install oracle-java8-installer
sudo apt-get install oracle-java8-set-default
java -version
2. 設定 Java 路徑:
請在家目錄中,執行指令「vi ~/.bashrc」,並且在文字檔案最上面插入文字「export JAVA_HOME=/usr/lib/jvm/java-8-oracle」,儲存並離開。最後,我們執行指令「source ~/.bashrc」,讓剛才插入文字的部分生效。
備註:
由於我們安裝 Oracle Java 的關係,可能會出現圖五的訊息,確認後(選Yes)就可以繼續安裝了。
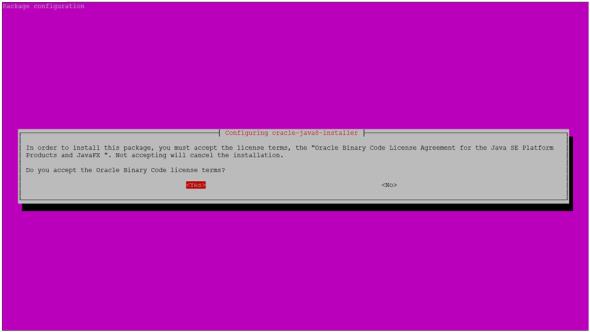
圖五 安裝 Oracle Java 的確認訊息
下載Hadoop
1. 下載流程:
cd ~
sudo wget http://www.us.apache.org/dist/hadoop/common/hadoop-2.7.1/hadoop-2.7.1.tar.gz
sudo tar -zxvf ./hadoop-2.7.1.tar.gz -C /usr/local
cd /usr/local/
sudo mv ./hadoop-2.7.1/ ./hadoop
sudo chown -R hadoop:hadoop ./hadoop
2. 設定配置
(1) 確認每台主機(master 跟其它 slave)名稱,是否分別為「master、slave01、slave02、slave03」:
sudo vi /etc/hostname
(2) 修改每台主機的 hosts 檔案:
sudo vi /etc/hosts
(3) 修改 hosts 內容,如圖六。
(4) 修改完成後,全部重新啟動,才能在終端機看到修正後的變化。
(5) 試著 ping 每一台,確認相互連通,如圖七。
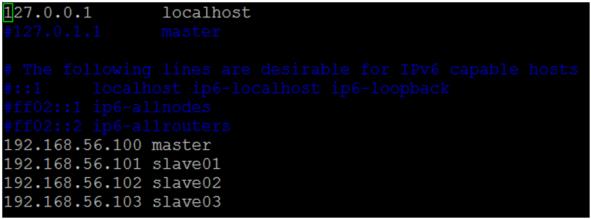
圖六 每台主機的 hosts 檔案內容
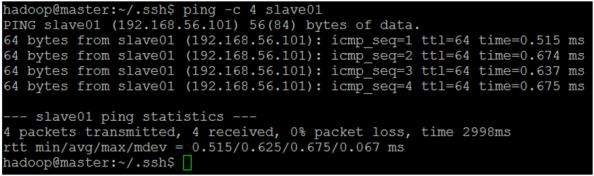
圖七 ping 每台主機,看看是否全部連通
SSH無密碼登入
1. 在這裡,我們要讓 master 可以不用密碼、直接登入 slave 等主機來進行操作。我們需要生成 master 的公鑰,所以我們要在 master 主機裡面執行以下指令:
mkdir ~/.ssh
cd ~/.ssh
ssh-keygen -t rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
scp ~/.ssh/id_rsa.pub hadoop@slave01:/home/hadoop/
scp ~/.ssh/id_rsa.pub hadoop@slave02:/home/hadoop/
scp ~/.ssh/id_rsa.pub hadoop@slave03:/home/hadoop/
2. 執行 scp 指令的同時,可能會需要輸入目標主機的密碼;完成後會提示傳輸完畢。接著我們要在 slave01、slave02、slave03 主機裡,將 ssh 公鑰保存到相對應的位置:
cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
3. 最後,我們回到 master
主機,執行下列指令,確認是否能無密碼登入(每一台 slave 都要連看看,成功就 logout,回到 master,再試下一台):
ssh slave01
ssh slave02
ssh slave03
配置叢集/分散式環境
1. 我們需要修改 /usr/local/hadoop/etc/hadoop 的五個配置文件:
slaves、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml
2. 進入配置文件資料夾
cd /usr/local/hadoop/etc/hadoop
配置內容如下:
|
檔案名稱
|
檔案內容
|
|
slaves
|
把原先裡面的「localhost」刪除,改成
slave01
slave02
slave03
|
|
core-site.xml
|
將原先只有
<configuration>
</configuration>
的部分,改成下列設定:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
</configuration>
|
|
hdfs-site.xml
|
將原先只有
<configuration>
</configuration>
的部分,改成下列設定:
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:50090</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
備註:因為我有 3 台 slave,所以 dfs.replicaton 值改成 3
|
|
mapred-site.xml
|
將原先只有
<configuration>
</configuration>
的部分,改成下列設定:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
|
|
yarn-site.xml
|
將原先只有
<configuration>
</configuration>
的部分,改成下列設定:
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
|
3. 接下來,我們要將 master 上面的 hadoop 資料夾打包,傳輸給所有 slave 主機:
cd /usr/local
rm -r ./hadoop/tmp
sudo tar -zcf ./hadoop.tar.gz ./hadoop
scp ./hadoop.tar.gz slave01:/home/hadoop
scp ./hadoop.tar.gz slave02:/home/hadoop
scp ./hadoop.tar.gz slave03:/home/hadoop
4. 傳輸完畢,我們分別到 slave01、slave02、slave03 主機裡,進行操作:
sudo tar -zxf ~/hadoop.tar.gz -C /usr/local
sudo chown -R hadoop:hadoop /usr/local/Hadoop
5. 完成後,我們回到 master 主機,準備正式啟動 Hadoop 軟體(「bin/hdfs namenode -format」這個指令,我們只要初次啟動的時候設定就好,以後不會用到):
cd /usr/local/hadoop/
bin/hdfs namenode -format
sbin/start-dfs.sh
sbin/start-yarn.sh
6. 啟動完成,若沒有錯誤訊息,我們可以透過「jps」指令,來查看各個主機啟動的程序。圖八為master 的服務程序,原則上會有「SecondaryNameNode、ResourceManager、NameNode」;圖九為其它 slave 的服務程序,原則上會有「DataNode、NodeManager」:
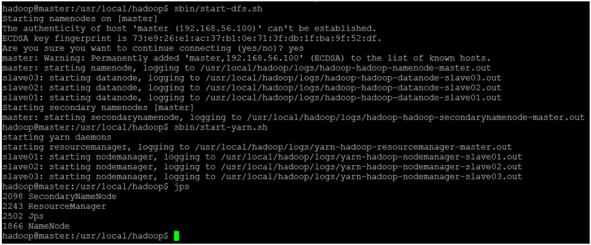
圖八 master 的Hadoop 啟動程序
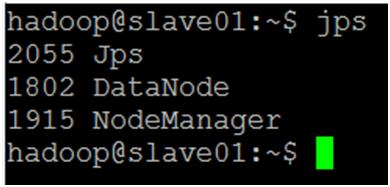
圖九 slave01 在 master 主機中顯示的訊息
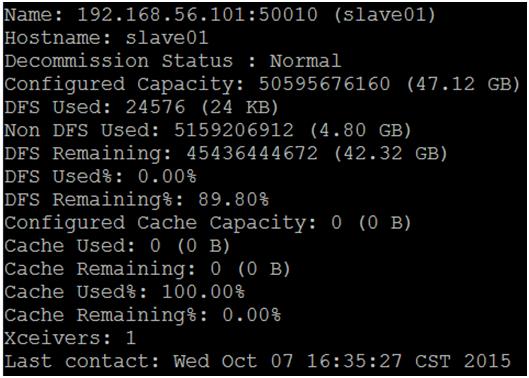
圖十 slave01 在 master 主機中顯示的訊息

圖十一 slave02 在 master 主機中顯示的訊息
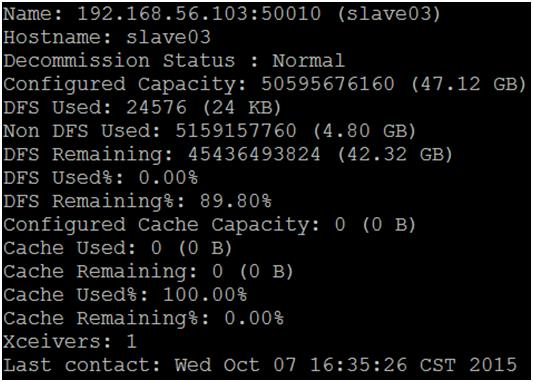
圖十二 slave03 在 master 主機中顯示的訊息
8. 當上述訊息出現的時候,代表 Hadoop Cluster 已經正式配置完成!
後記
透過一步一步地安裝Hadoop Cluster配置,完成後,想必滿懷成就感,接下來尚有MapReduce等議題需要探討,惟篇幅有限,無法完整討論。建置過程有些繁雜,讀者必須反覆安裝與測試,方能熟悉Hadoop安裝過程。
參考資料
[1] Hadoop下載頁面
http://hadoop.apache.org/releases.html
[2] Ubuntu 12.04 安裝 Oracle Java 7
http://way3sec.blogspot.tw/2012/07/ubuntu-1204-oracle-java-7.html
[3] Hadoop集群安裝配置教程_Hadoop2.6.0/Ubuntu 14.04
http://www.powerxing.com/install-hadoop-cluster/
[4] Hadoop安裝配置簡略教程
http://www.powerxing.com/install-hadoop-simplify/