作者:何宗諭 / 臺灣大學計算機及資訊網路中心程式設計組幹事
本文以簡單的範例探討如何利用Python實現資料分析與機器學習,為了更容易介紹本範例,將介紹如何使用Jupyter Notebook進行程式開發與呈現,並且利用豐富地python套件將資料視覺圖像化,且實作機器學習的方法進行資料分析。本文主要介紹的套件有Keras、TensorFlow、Scikit-Learn、Matplolib,礙於篇幅有限本文將花比較多時間介紹Keras這個工具,期望讀者在閱讀文這篇文章後,能夠自己活用開發屬於自己的機器學習方法。
一、前言
現在網路上有很多關於機器學習的資源,對於機器學習的研究相對的是比以前容易很多。但是瞭解機器學習是一回事,把機器學習應用在生活的數據上又是一回事,所以我們不只要瞭解機器學習的方法,更希望能快速實作機器學習的方法。因此如果能利用已知的工具套件,完成我們所需的功能,才是我們的目標。本文並不會花太多時間介紹機器學習內容,僅利用一些網路的資源介紹主流的開發套件,並且預設有些讀者從未使用過這些套件。第一部份將介紹如何在自己的電腦上安裝開發環境,並預期讀完本文後,可以在自己的電腦上執行Github上的程式碼,由於Linux的相關文章比較多,本文將把重點放在Windows環境上。
二、環境建置
假若有些讀者對於Python環境沒有那麼熟悉,且不太清楚如何在電腦上安裝這些機器學習的開發工具,所以我們將花一些時間教大家如何在自己的電腦上安裝Python工具。由於蠻多的機器學習方法會利用到GPU加速,所以本文也會提供兩種不同的套件安裝方式,但主要是以CPU為主的開發工具。
本文將花較多時間介紹如何在Windows上建置的開發環境,因為Linux的安裝相容性較高,大部份的疑難都可以在網路上找到相關的教學文,所以本文將以Windows為主。
其中有一些Python套件(例如SciPy),有蠻大的機會在Windows版本上安裝會出現問題,所以無法利用pip install (假定要用Python的套件管理)的方式進行安裝,筆者也試過直接安裝最新版本pip install git+https://github.com/scipy/scipy.git,甚至到SciPy官網https://www.scipy.org/install.html 上去查詢,也無法找到可以用的wheel安裝。
Windows packages(引用官網的介紹)
Windows does not have any package manager analogous to that in Linux, so installing one of the scientific Python distributions mentioned above is preferred. However, if that is not an option, Christoph Gohlke provides pre-built Windows installers for many Python packages, including all of the core SciPy stack, which work extremely well.
官網建議我們去接去非官方的網站下載安裝檔,這邊會出現一個困擾,因為不是用Python的套件管理來安裝,可能會有相容性的問題,又或者就算今日可以正常安裝,此非官方安裝檔可能隨時間消失或更新,本文的方法可能在未來就不適用。所以本文接下來將介紹一個最簡單的方法。
所以筆者強烈建議,如果想在Windows上建置環境,建議使用Anaconda來建置,本文也會教大家用Anaconda,從零一步一步將開發環境建構。至於Linux的安裝環境比較簡單,建議大家可以自行搜尋網路,若有疑問也可以像筆者本人詢問。
安裝環境
1. Windows 7 64-bit (Windows 10 方法一樣)
2. Anaconda 4.3.1 for Windows
3. Python 3.6
4. TensorFlow CPU only
1. 安裝Anaconda:
首先到Anaconda的官網去進行下載安裝檔,此檔案約400MB,且安裝完會需要2GB的空間,所以確認電腦上有足夠的安裝空間。
圖一、ANACONDA 官網
在https://www.continuum.io/downloads#windows 安裝Python 3.6的版本,此程式將預設安裝在C:\ProgramData\Anaconda3。
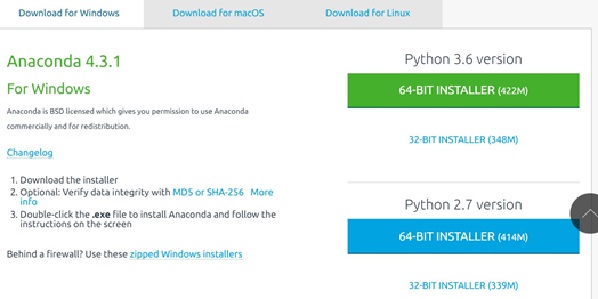
圖二、安裝Python 3.6版本
圖三、預設安裝位置
為了確認是否安裝成功,開啟Windows cmd(或使用Anaconda Prompt,安裝Anaconda後即可在程式集裡找到)後,輸入:
Conda -V
Python -V
確認是否看到的版號是正確的。因為如果有些使用者之前已經在電腦上安裝其它的Python環境,可能系統變數會導至另一個版本,所以建議使用Anaconda提供的Anaconda Prompt
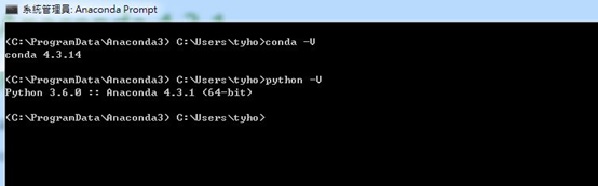
圖四、安裝Anaconda完成
2. 建立Python虛擬環境:
在Linux上建立Python虛擬環境指令通常使用virtualenv指令,在Anaconda環境下,就使用conda create,在建立之前,我們先來討論一下,為何要使用虛擬環境,而不直接安裝呢?
若在開發環境下一次安裝所有的套件,可以完整使用看起來是最便利的,但是由於這些Python套件都是由不同的開發團隊開發,所以常常存在一些相依性的問題。比如說要安裝Keras之前,必須先安裝NumPy和SciPy,可是SciPy可能又跟某一版的Python在Windows上有相容性的問題,所以又必需將Python設為3.5版才能安裝,如此一來必會影響整個系統環境,並且隨時間越來越複雜。甚至我們想要嘗試某一個開發套件,又不想因此升級原有的版本而導致程式無法使用,所以我們需要一個像沙盒的虛擬環境進行嘗試又可以隨時轉換環境,因此建議不管是什麼樣的開發流程,建議都在虛擬環境進行安裝及開發。更多conda的環境設定可以參考https://conda.io/docs/using/envs.html。
假設我們今天要開發一個Keras套件,並將環境命名成py-Keras(名稱可隨意定),並預設為Python3.5版本,所以利用conda create以下的指令:
conda create --name py-keras python=3.5
這邊可能會有一些疑惑,如果使用conda create --name py-keras即可產生一個3.6的環境,為什麼還要特別定義3.5版本號,那是因為在現行的TensorFlow的套件,僅支援到3.5版,可以參考這邊。未來可能會相容,但在本範例寫作時,還是以3.5為主。圖五顯示相容性的問題:
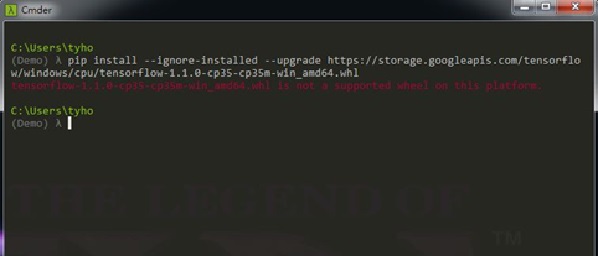
圖五、TensorFlow相容性的問題
因此改使用指定python=3.5來安裝,conda就會幫我們管理版本的相依性,並安裝相關的套件。
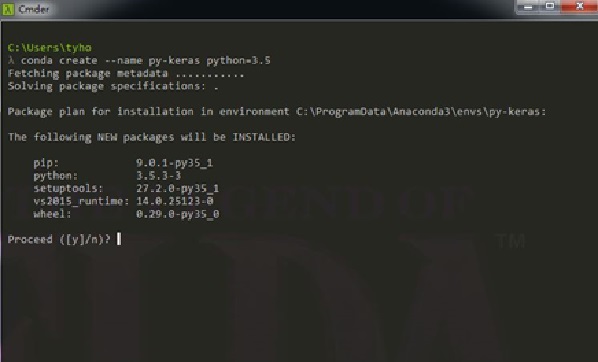
圖六、新增Python=3.5環境
圖六A、建立虛擬環境完成
環境設好後,使用activate指令開啟指定環境,並進入python套件安裝
activate py-keras
# deactivate py-keras 離開環境
3. 安裝Python 套件:
在Python環境裡,我們習慣使用pip install(或pip3),但在Windows上,如前面所說,建議使用conda install來管理套件。所以安裝以下的套件:
conda install scipy
conda install theano
conda install scikit-learn
conda install matplotlib
但這邊會出現一個新的問題,雖然conda install很方便,但至本文寫作時,還無法安裝我們所需的TensorFlow和Keras,也就是以下指令會顯示找不到套件。
conda install tensorflow keras
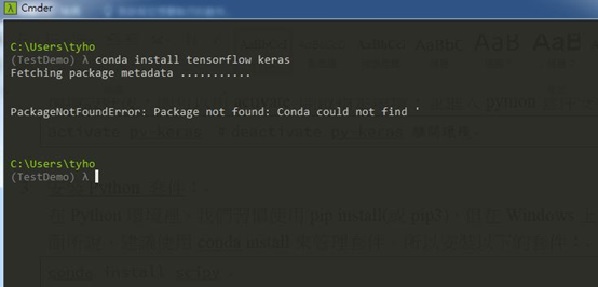
圖七、找不到開發套件
雖然不能用conda install,起因於套件比較新,conda還沒納入套件管理,好在Google網站上有詳細的介紹安裝方法。 這邊介紹了兩個不同的安裝檔,一個是給CPU使用,一個是多了GPU使用,因為本文僅討論簡單的範例,所以我們選用CPU版本,如以下指令:
pip install --ignore-installed --upgrade
https://storage.googleapis.com/tensorflow/windows/cpu/tensorflow-1.1.0-cp35-cp35m-win_amd64.whl
本指令日後版本可能會更新,所以請讀者日後可以自行參考最新的安裝方式https://www.tensorflow.org/install/install_windows。
因為Keras是相依於TensorFlow來開發,所以必須先安裝TensorFlow後才能再安裝 Keras,指令如下,使用pip install去官網抓取最新的版本回來安裝:
pip install git+git://github.com/fchollet/keras.git
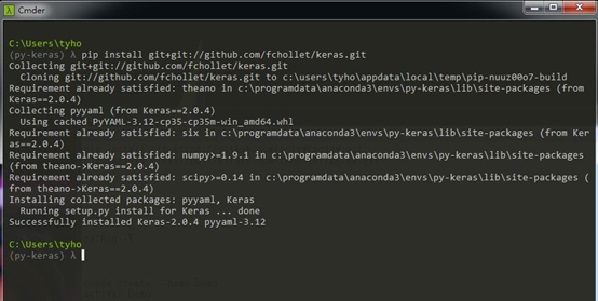
圖八、Keras安裝成功
4. 開啟Jupyter Notebook: 為了讓更便利將資料視覺化呈現,所以接下來的範例討論採用了Jupyter notebook來呈現(或用iPython notebook),所以安裝jupyter如下,並開啟notebook:
conda install jupyter
jupyter notebook #開啟notebook
執行jupyter notebook後,即會在localhost:8888下新增一個網路APP,到了這一步,我們終於可以開始執行我們的程式了。更進一步的Jupyter應用可以參考https://jupyter-notebook.readthedocs.io/en/latest/。
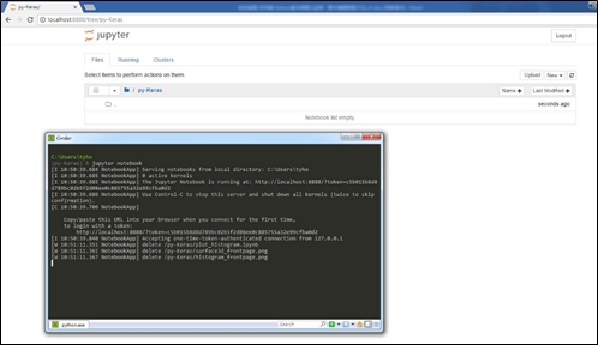
圖九、啟動Jupyter
首先,我們來跑一個簡單的範例,確保大部份的套件都有完整安裝好(可用conda list指令查看)。進入自行定義的資料夾(本範例使用py-Keras),並新增Python 3 notebook。
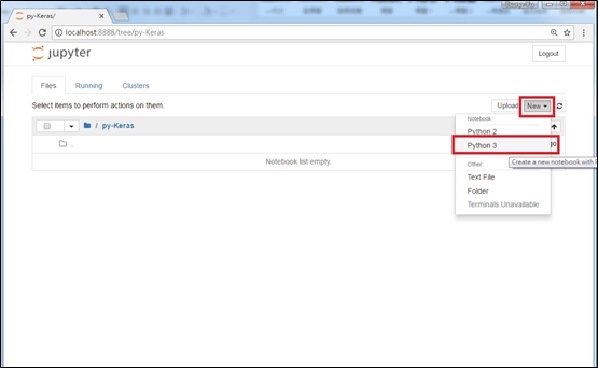
圖十、新增notebook
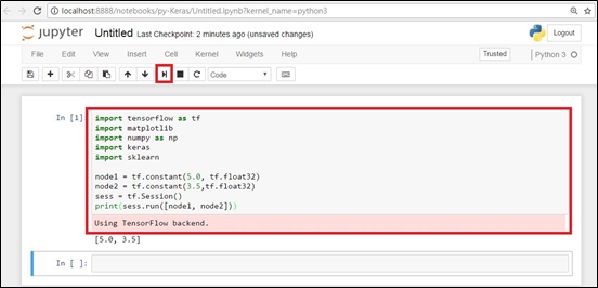
圖十一、簡單範例
如圖十一,將以下程式碼貼到notebook的框架裡,按shfit+Enter即可執行本段程式碼,或使用上面的按鈕。
import tensorflow as tf
import matplotlib
import numpy as np
import keras
import sklearn
node1 = tf.constant(5.0, tf.float32)
node2 = tf.constant(3.5,tf.float32)
sess = tf.Session()
print(sess.run([node1, node2]))
這是一個簡單的TensorFlow範例,建立兩個只有輸出的node,並將兩者加總在一起,並利用TensorFlow的Session(),執行此結果,如果沒有出現No module named 這類的錯誤訊息,就表示這個模組正確安裝,反之出現錯誤,則回到上一步去檢查是否沒有安裝好套件。
三、Matplotlib 資料視覺化的呈現
我們除了分析資料外,更希望能夠馬上快速檢查程式碼是否正確,所以希望能將資料圖像立即顯示在notebook上,這也是為什麼我們使用Jupyter進行開發的原因。圖十二介紹如何將一些資料呈現在座標圖上。
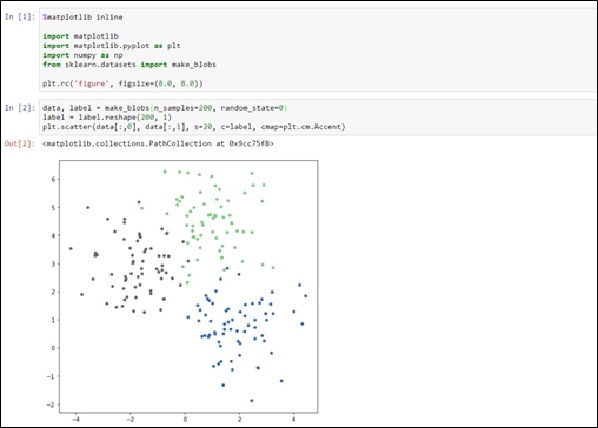
圖十二、Matplolib範例
程式碼如下:
%matplotlib inline
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
from sklearn.datasets import make_blobs
plt.rc('figure', figsize=(8.0, 8.0))
data, label = make_blobs(n_samples=200, random_state=0)
label = label.reshape(200, 1)
plt.scatter(data[:,0], data[:,1], s=20, c=label, cmap=plt.cm.Accent)
簡單說明本程式的重點:
(1) 使用matplotlib.pyplot進行畫圖,使用plt.rc定義圖片大小。
(2) 利用sklearn.datasets載入資料,本範例使用make_blobs,或用circle, API的使用可以參考,make_blobs和make_circle。
(3) n_samples 取的點數。
(4) reshape(200,1) 將200個點的陣列轉成向量,其中label的值為0或是1,在圖形上顯示兩種不同的顏色。
(5) data 為200x2的矩陣,其中data[: ,0] 表示X座標值,data[: ,1]為Y座標值,Color使用label來區分,s為資料的圖形大小。Cmap則是color map的方式。
另外使用make_circles的結果,如圖十二A。
from sklearn.datasets import make_circles
data, label = make_circles(n_samples=200, random_state=0, factor=0.8, noise=0.1)
label = label.reshape(200, 1)
plt.scatter(data[:,0], data[:,1], s=40, c=label, cmap=plt.cm.Accent)
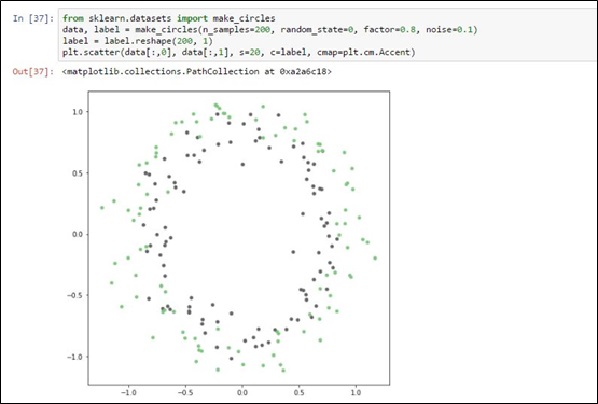
圖十二A、make_circle範例
以上是我們簡單地介紹Matplotlib套件,更多的範例可以參考其官網https://matplotlib.org/examples/index.html,這邊就不多加解釋。
四、TensorFlow 介紹
資料視覺化只是我們的第一步驟,我們真正的目標還是需要將資料分析,如圖十二和圖十二A,我們希望存在一個Model可以將不同的label進行分類。本文最後將介紹如何利用Keras套件進行機器學習,不過因為Keras是用到TendorFlow的底層,所以這一小節將簡單介紹TensorFlow,然後在下小節利用比較抽象層級來完成目標。
TensorFlow的介紹參考https://www.tensorflow.org/get_started/get_started,本文將以這篇介紹TensorFlow,介紹核心概念。
TensorFlow的開發概念是來類神經網路,利用多個結點組合成一個網路集合,有興趣的可以自行上網搜尋相關文章。所以對TensorFlow來說,其tensor就是一個最小的神經元,也可看成一個網路node,這個node可以輸入、運算、且輸出運算結果。所以TensorFlow的Model其實就只是作三件,定義1)各個node功能,2)各node間的連結方式,3)輸入、輸出的維度。然後有了Model之後在開始train。
在設計一個類神經網路前,我們先來看一個簡單的範例,假設我們要實作一個如圖十三這樣的網路,其中x1、x2;x3是輸入,而變數是a和b,此變數需要學習,並且在之後變化,這些變數就是我們一般所說的權重。
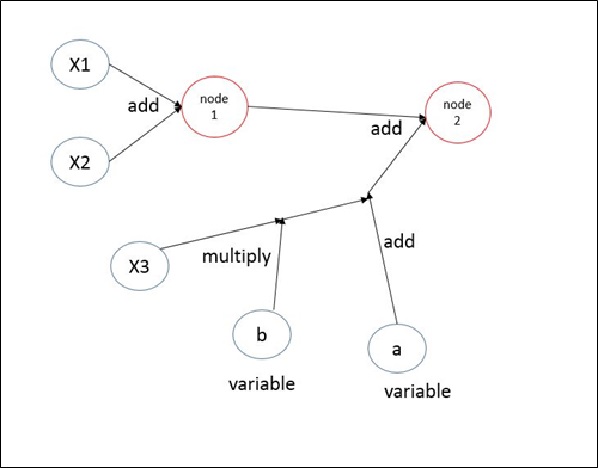
圖十三、簡單網路
我們將圖十三的架構實作在,圖十四上。
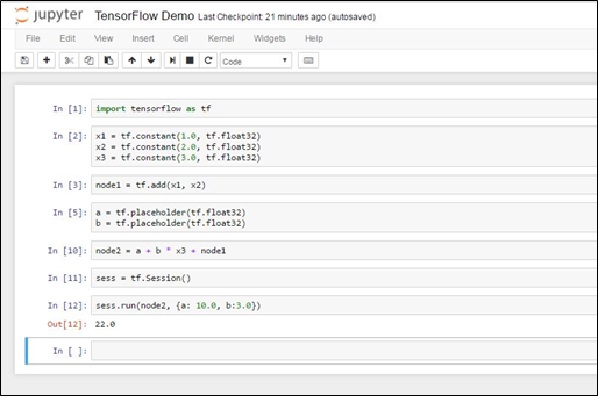
圖十四、簡單的Tensorflow範例
其程式碼如下:
import tensorflow as tf
x1 = tf.constant(1.0, tf.float32)
x2 = tf.constant(2.0, tf.float32)
x3 = tf.constant(3.0, tf.float32)
node1 = tf.add(x1, x2)
a = tf.placeholder(tf.float32)
b = tf.placeholder(tf.float32)
node2 = a + b * x3 + node1
sess = tf.Session()
init = tf.global_variables_initializer()
sess.run(init)
sess.run(node2, {a: 10.0, b:3.0})
程式重點: (1) x1、x2、x3 是輸入,我們使用constant使其為定值。
(2) node1 是 x1和x2的相加。
(3) a,b是可以調變的變數,注意到這邊,一旦我們定義了變數,我們就必須先初始化變數。
(4) 最後使用session.run執行一輪,即結束。
接下來我們介紹另一個基本的範例
Linear Model
這個範例介紹了如何將一個資料向量X=[x1, x2, x3, x4],進行向量線性運算 Y = W*X + b,其中W就是權重。所以如圖十五,經過線性運算後,可以得到一組Y向量。如果我們希望能夠訓練W的值,我們就需要完成像圖十六這樣的架構。
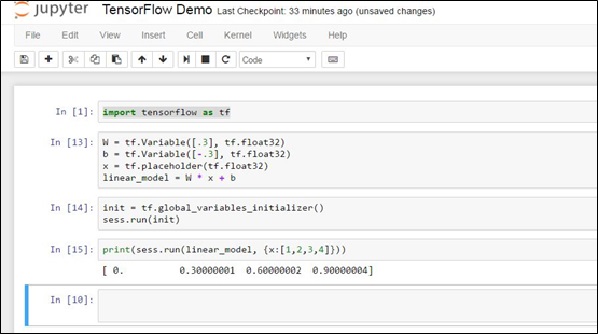
圖十五、簡單的Tensorflow範例
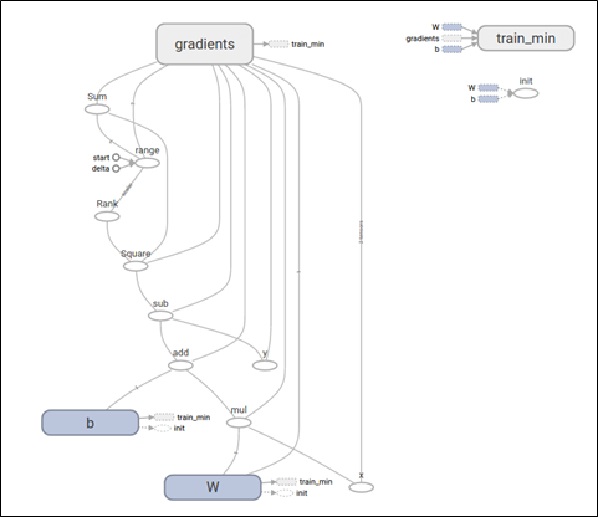
圖十六、Tensorflow範例(https://www.tensorflow.org/get_started/get_started)
如官網的圖十六所示,我們希望完成一個機器學習方法,就必須先決定好網路架構和Training的流程,有興趣的人可以自行參考網站內容,而本文接下來則是介紹利用Keras進行Training。
五、Keras 介紹
其實Keras底層也是利用tensorflow來實作,可以把Keras想成更抽像的API,也就是說如上一節所說,我們為了要實現類神經網路,我們必須先利用程式碼定義網路架構,而Keras則是提供了API簡化了流程。
利用Keras的API來建構網路的(文件可參考https://keras.io/layers/core/),若我們想建立一個輸入為10筆、輸出為2筆的網路架構,程式如下。其中Model裡的Dense是預設輸入為10,輸出為2的節點。
from keras.models import Sequential
from keras.layers import Dense
model = Sequential()
model.add(Dense(2, input_shape=(10,)))
model.compile(optimizer='sgd')
model.summary()
如果想要在中間多加2層的網路,在不用動到其它程式碼下,只要在中間增加model.add即可,如下程式碼即建立兩層hidden layer,且各層為10的節點數量:
from keras.models import Sequential
from keras.layers import Dense
model = Sequential()
model.add(Dense(2, input_shape=(10,)))
model.add(Dense(10))
model.add(Dense(10))
model.compile(optimizer='sgd', loss='binary_crossentropy')
model.summary()
其中關於sgd和loss function的討論,可以在機器學習的網站找到相關內容,這裡就不多加著墨。因為Keras已經幫我們處理好了Model的建置,所以有了Model之後後,我們就可以用資料進行Model training,就留在下一節介紹。
六、利用Keras進行Model訓練。
本段我們參考github.com上的原始碼進行改寫,這邊就不提供原始碼,有興趣的讀者可以自行拿網路上範例進行改寫,本文參考的範例如下。
https://github.com/nailo2c/PyCon2017TutorialRL/blob/master/MLP_Keras.ipynb 。
並將程式套用在一個新的問題上,我們使用make_circles這個Dataset,如圖十七。
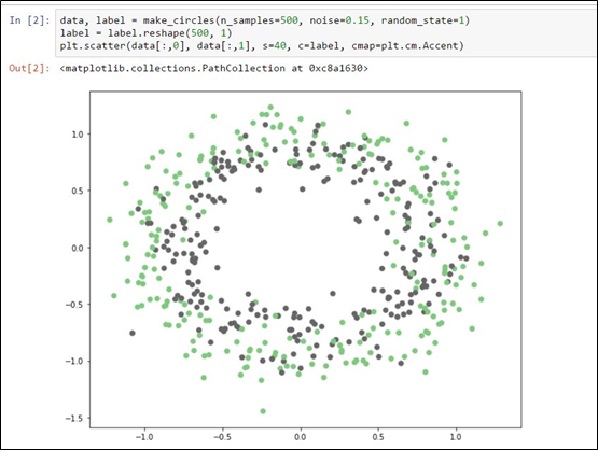
圖十七、make_circles Dataset
如圖十七,為了增加亂度,將Noise定義為0.15。
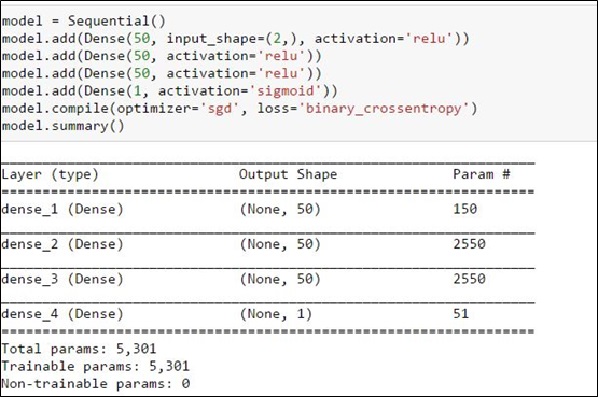
圖十八、定義Model
在圖十八,設定找最佳解的方法為Stochastic gradient descent(SGD),輸入與輸出的Loss Functon使用cross entropy,設定每一層有50個節點,並有有兩層hidden layer,最後統計出約有5301個變數要訓練,執行約1000次,大約1~2分鐘內,就可以跑出圖十九的結果,如我們預期般產出一個圓的Model,使Model可用於區分裡和外的資料分析。
若沒有這些Python套件,光是實作sgd演算法就需要耗費大量的時間,可是這部份Keras已經幫我們實作完成了,所以我們更可以專注在研究怎樣的架構適合解決怎樣的問題。這也是本文介紹Keras的主要目的。
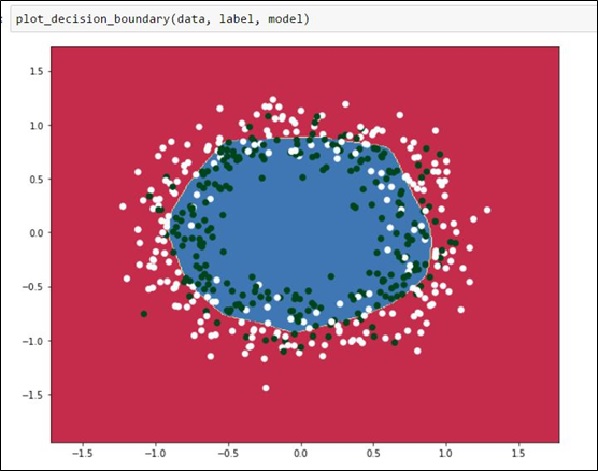
圖十九、訓練完的Model
七、結論
本文簡單地介紹從Matplolib、到TensorFlow、最後再利用Keras的範例程式訓練一個類神經網路,並且快速地得到一個還算不錯結果的Model。如果要瞭解這些套件(Matplolib、TensorFlow、Keras),可能需要大量的篇幅才能解釋完,所以本文將目標放在,對於已熟知機器學習的讀者,如何用現成已知的套件,用最短的時間完成所需的目標。
參考資料
[1] Anaconda 官網
https://www.continuum.io/downloads
[2] Anaconda環境管理
https://conda.io/docs/using/envs.html
[3]TensorFlow for Windows
https://www.tensorflow.org/install/install_windows
[4] Jupyter Notebook
https://jupyter-notebook.readthedocs.io/en/latest/
[5] TensorFlow Introduction
https://www.tensorflow.org/get_started/get_started
[6] Matplotlib Example
https://matplotlib.org/examples/index.html
[7] Keras Documents - Layers
https://keras.io/models/sequential/
[8] Keras Example Code by nailo2c (github.com)
https://github.com/nailo2c/PyCon2017TutorialRL