作者:周秉誼/趨勢科技
當深度學習模型變得越來越龐大、越來越複雜,想使用這麼龐大的深度學習模型,不止要花費更大量的訓練時間,也要使用更多的記憶體和計算資源,這個時候就會想要使用硬體來加速深度學習的計算工作。本文將針對深度學習應用常見的硬體和加速方式,包括CPU、GPU、和TPU進行介紹。
前言
隨著各式各樣的深度學習研究出爐,深度學習也廣泛地應用在人們的日常生活之中,很多我們習以為常的資訊服務背後,都有深度學習的核心。然而在人們追求更強大的深度學習應用的同時,深度學習模型也變得越來越龐大、層數變得更深、參數(parameter)變得更多、深度學習網路也越來越複雜。想使用這麼龐大的深度學習模型,不止要花費更大量的訓練(Training)時間,也讓模型在預測(Predicting)時要使用更多的記憶體和計算資源。當模型訓練和預測要花費大量計算資源時,就會想要使用硬體(Hardware)來加速計算工作。硬體和軟體不同,受到成本、應用環境、甚至尺寸、用電量等因素的限制,在硬體設計之初,就要依照不同的應用情境規劃,才能做出成功的硬體。本文將針對深度學習應用常見的硬體和加速方式,包括傳統中央處理器(CPU)、圖形處理器(GPU, Graphic Processing Unit)、和專為深度學習設計的張量處理器(TPU, Tensor Processing Unit)進行介紹。
深度學習基本計算工作
深度學習和一般的機器學習一樣,主要分為兩大步驟: 訓練(Training)和推論(Inference)。一般而言,大量的計算資源會花費在訓練階段,因為訓練階段會對所有的訓練資料(Training data)進行一次又一次、數十至上百個迭代(Iteration)的計算,才能得到效果夠好的深度學習模型。
以AlphaGo Zero來說,使用上千個TPU的硬體加速,也需要幾天的時間才能訓練出強大的深度學習模型。如果只用單一CPU、沒有使用硬體加速,可能要花費數年的時間才能到同樣的效果。這樣一來,深度學習的研究和應用將無法普及,因此也突顯了硬體加速對深度學習的重要性。
深度學習的訓練階段中,主要的計算工作包括各個神經網路層(Neural network layer)的神經元(Neuron)把不同的輸入資料乘上參數,再將結果傳遞給下一層當成輸入;到達最後一層後將結果的誤差(error),依所選的誤差函數(Error function)進行梯度(Gradient)計算;並將梯度以反向傳播(Backpropagation)方式,對模型中每一個神經元的參數進行更新。
深度學習預測階段的計算工作就只有第一個部份,各個神經網路層把輸入資料乘上參數、將結果傳遞給下一層當成輸入、到達最後一層產生出模型預測的結果。但不論是訓練階段或預測階段,這些計算工作有很大一部分都是向量矩陣乘法。而向量矩陣乘法的計算,一直是科學計算和數值計算很重要的元素。
CPU的硬體加速
雖然相較於GPU或TPU等特化的處理器,CPU的計算能力在深度學習的計算工作並沒有特別突出之處,但CPU的硬體還是有一些針對向量矩陣乘法加速的功能,也有豐富的矩陣計算函式庫可以使用。對於向量矩陣乘法,在CPU上可以使用SIMD(Single instruction, multiple data)指令集,如Intel CPU中的SSE(Streaming SIMD Extensions)指令集來進行加速。另外,當代的CPU大多有多個核心(Multi-core),也可以使用多執行緒(multi-threading)將矩陣乘法平行化,進而加速矩陣乘法的計算。
BLAS(Basic Linear Algebra Subprograms)是一個歷史悠久的向量矩陣乘法應用程式介面(API)標準,各大處理器廠商及開放源始碼社群都有開發針對不同CPU最佳化(Optimization)的BLAS函式庫。在這些BLAS函式庫中,各個函式的實作上也會依照CPU中的快取記憶體(Cache)大小來調整矩陣乘法的Block size,保持快取記憶體的Hit rate,來提高計算效率。
而深度學習中的向量矩陣乘法計算,就可以直接使用其中的GEMM函式(General Matrix to Matrix Multiplication)或GEMV函式(General Matrix to Vector Multiplication),部份深度學習硬體的應用程式介面,也會依循BLAS的介面,方便程式開發者在不同計算硬體間轉換。
GPU的硬體加速
顯示卡或整合性的顯示晶片已經是現在電腦的標準配備,用來加速處理影像繪製及螢幕輸出,而顯示卡核心晶片的運算能力一直直線成長,有了比中央處理器更強大的運算能力,產生了圖形處理器這個概念。目前最常見的GPU計算環境,就是NVIDIA的CUDA(Compute Unified Device Architecture),而NVIDIA也在CUDA的基礎之上打造了cuDNN函式庫,方便更上層的深度學習套件呼叫,就可以直接利用GPU加速深度學習的計算。而GPU最主要的加速原理,是利用GPU中成千上百個計算核心,將深度學習中的矩陣計算分散進行。
NVIDIA GPU是目前最常見最容易取得、也有最多深度學習套件使用的深度學習加速硬體。最受歡迎的深度學習套件如TensorFlow、Pytorch等,都可以直接使用GPU來對深度學習的訓練和預測加速。對於初學深度學習的朋友,NVIDIA GPU也是最方便入門的深度學習硬體,就算不特別購買,也可以利用電腦所配備的中價位、不到五千元的顯示卡,就可以來進行深度學習的計算和學習。如果想使用更高級的GPU,也只要不到兩萬元就有接近頂級的計算能力。想要有更高的計算能力,也可以銜接NVIDIA計算專用的Tesla系列。不過購買和選擇NVIDIA GPU時要注意各個GPU世代所支援的CUDA版本,深度學習的套件和cuDNN函式庫可能會不支援太舊的CUDA版本。
TPU的硬體加速
TPU是Google所設計研發、專為深度學習使用的「特殊應用積體電路」 (ASIC, application-specific integrated circuit)。不同於CPU或GPU,在設計之初ASIC就只能進行特定的一項計算工作,而沒有隨著不同程式改變計算工作的彈性。因此ASIC是犧牲了計算工作的彈性,來換取較低的生產成本、和對單一計算工作效能的最大化,通常也可以讓能源使用效率更好。這也不難想見Google選擇ASIC成為TPU的架構的原因。
TPU既然是專為深度學習而設計的ASIC,它最核心的計算工作當然就是向量矩陣乘法,所以TPU的計算核心就是矩陣乘法計算單元(MMU, Matrix Multiply Unit),在TPU中MMU就佔了超過四分之一的空間。MMU是由256乘256列、一共65,536個乘數累加器(MAC, Multiply Accumulator)組成,每一個乘數累加器會把兩個輸入的數字相乘、再把結果跟前一輪加總的數字累加,這也是矩陣乘法中最基本的操作。值得注意的是TPU中的MAC是並不是以一般的16位元浮點數(Floating point)進行乘法計算,最早的TPU是以8位元乘法,也讓硬體的複雜度大幅降低。
在TPU的MMU中,為了降低記憶體存取的時間和能源消耗,使用了Systolic Array來進行矩陣乘法。MAC以二維排列,排在上方和左邊的MAC可以把前一輪收到的數字,傳給下方和右邊的MAC當成乘法的輸入數字。所以一個輸入值只會從記憶體中讀取一次,就一直以傳遞的方式在MMU中不同的MAC間移動,直到矩陣乘法完成。而每一輪乘法累加的結果就儲存在每一個MAC中,方便和下一輪乘法的結果累加。當所有的輸入數字都在MMU中傳遞完畢,矩陣乘法也就完成了。因此在TPU中使用Systolic Array來進行矩陣乘法,可以有效利用到256乘256二維排列的MAC,大量將矩陣乘法平行化。
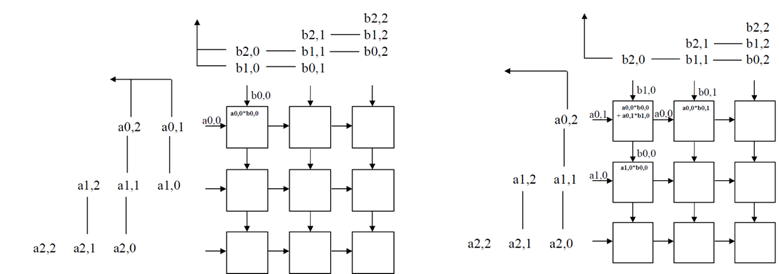
圖1. Systolic Matrix Multiply
總結TPU成功的原因,包括將矩陣乘法平行到大量的MAC、在MAC中使用較低精確的浮點數計算等等。目前TPU已經演進到第三個世代,第一代TPU最大的缺點就是不能進行深度學習模型的訓練,但從2017年推出的第二代TPU就可以進行訓練了,而且也提高了MAC中浮點數的精確度,計算能力更增加到45TFLOPs。2018年推出的第三代TPU更將計算能力提高到二代TPU的八倍。不過目前想要使用TPU,只能在Google的GCP平台上使用。目前GCP平台上提供了第二代和第三代TPU,除了讓一般人進行運算之外,也是Google各項產品和服務中的深度學習最重要的運算資源,Google的各個深度學習研究,也會利用TPU來加速模型訓練,如AlphaZero及BERT都有使用TPU加速訓練。

圖2. 第一代TPU和第二代TPU (From: Google)
Edge Computing與深度學習硬體
想要讓深度學習更加深入及普及在我們的生活之中,除了用雲端計算(Cloud Computing)服務中的GPU和TPU來加速以外,還需要讓每個人周圍的手機和IoT等裝置也有足夠的計算能力,才能降低網路傳輸的延遲、真正讓深度學習的成果無所不在。所以各大晶片廠商也正在發展更為輕量化的深度學習硬體,可以放在嵌入式系統之中,以提供給Edge computing環境使用,如NVIDIA的Jetson、Intel的Movidius、TPU的Edge版等等。Google出品的Pixel手機也引進了計算攝影(Computational Photography)的概念,內建了Pixel Visual Core硬體晶片,用來加速照片處理、自動化進行後製、讓拍出來的照片效果更好。
一旦深度學習硬體加速的Edge Computing晶片全面進入手機和IoT裝置後,不只可以減低個人隱私資料送到雲端計算的風險,相信也能大幅改變深度學習訓練過程,讓每個人的手機都能在深度學習訓練過程有所貢獻,並提供更個人化的深度學習模型。