作者:陳淑萍 / 臺灣大學計算機及資訊網路中心程式設計組程式設計師
SQL指令敘述調校是最佳化SQL指令敘述的過程,以建立作佳化的SQL指令來更有效率地存取資料庫,包含SELECT, INSERT, DELETE和UPDATE操作指令。SQL指令敘述調校的目的則是在建立有效率的SQL查詢指令,其調校過程是從查詢指令的元素開始,特別針對WHERE條件子句。
查詢最佳化
一般來說,SQL Server在執行查詢時,最先是採用叢集索引進行掃描,接下來是採用非叢集索引進行掃描,最後才是採用整個資料表進行資料掃描。
以MS SQL Server為例,執行計畫(Execution Plan)可以在SQL Management Studio中產生圖形化介面的查詢執行計畫,它是SQL Server查詢最佳化模組選擇的資料擷取方法,我們可以透過此執行計畫來進行查詢指令的最佳化。
若要再MSL SQLL ManagementL Studio中顯示執行計劃,使用者必須擁有所有查詢資料庫的SHOWPLAN權限,要啟動執行計劃,可由兩個地方開啟。
1. 由選單中開啟,可選擇只『顯示估計執行計劃』或『包括實際執行計劃』。
圖一
2. 由工具列中開啟
圖二
3. 執行結果,如下圖所示。
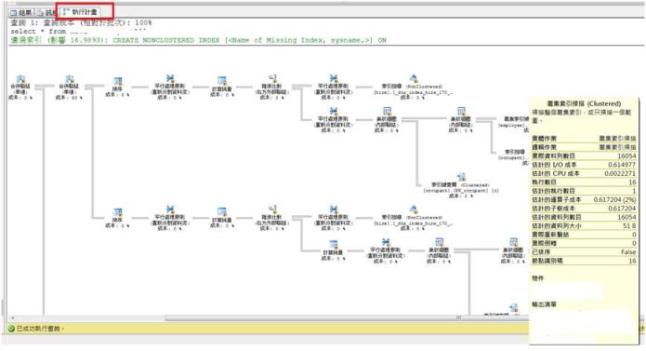
圖三
如何建立有效率的SQL查詢
SQL指令調校過程是特別針對WHERE條件子句,因此條件可以決定查詢最佳化與否,如何建立有效率的SQL查詢指令,以下幾點提供參考:
1. 避免在使用LIKE運算子比對萬用字元(%)開頭的字串
LIKE運算子在WHERE子句中,提供很大彈性的查詢條件,但也因為如此所以使用者常常會濫用LIKE。在使用LIKE與萬用字元時,需要特別注意萬用字元的位置。萬用字元的位置是在常數之後,例如:'林%'可以使用索引來執行查詢;但若是萬用字元在常數的開頭,則不會使用索引來執行查詢,只能使用資料表掃描來執行查詢。
--使用索引
SELECT * FROM EMPLOYEE WHERE FirstName LIKE '林%'
--不使用索引
SELECT * FROM EMPLOYEE WHERE FirstName LIKE '%林'
2. 避免對索引值的欄位進行運算或使用函數
使用者時常在WHERE子句中用某個欄位的資料做運算後再來做搜尋與比對,雖然這個欄位已經建立索引,也不會使用索引來執行查詢而是使用資料表掃描來執行查詢。這樣會導致查詢最佳化模組無法使用索以來提升效能。例如,要找出公司中年薪超過700000的人員名稱及每月月薪。SQL查詢指令如下所示:
SELECT Name, salary
FROM Employee
WHERE salary*12 >= 700000
在估計執行計畫中,雖然salary已經建立索引,但是查詢指令中是先做了運算(乘以12後再和700000做比較),找出大於700000的資料,所以是以資料表掃描的方式來執行查詢。
但若將SQL查詢指令改寫,則執行計劃就會以索引來執行查詢(先算出700000除以12得到運算結果後,在用索引來搜尋),如下所示:
SELECT FirstName, LastName, salary
FROM Employee
WHERE salary >= 700000/12
WHERE條件的欄位若使用函數,會讓建立在欄位的索引無法使用。但真正對資料庫效能影響最大的,是當資料表有大量筆數的資料時,則在查詢時就呼叫函數的次數就等於資料的筆數,這才是真正的影響效能的主要原因。這種情況在系統開發初期可能感覺不出,但當系統上線且資料累積到一定的筆數後,這些查詢語法就有可能造成資料庫效能的下降。例如,要找出公司中姓林的員工資料時,如下所示:
--若有10萬筆員工資料,就會呼叫SUBSTRING函數10萬次
SELECT FirstName, LastName, Title
FROM EMPLOYEE
WHERE SUBSTRING(FirstName,1,1) = '林'
建議改用下方的SQL查詢指令,如下所示:
SELECT FirstName, LastName, Title
FROM EMPLOYEE WHERE FirstName LIKE '林%'
3. 避免使用OR運算子
使用OR運算子時需要『所有的』條件都有可用的索引才能使用索引提升查詢效能;但若是使用AND運算子則只需要有一個條件擁有索引就可以大幅提升查詢校能。換句話說,在使用OR運算子時,只要有一個條件沒有可用的索引,則其它條件的索引也不會被使用,建議使用者可以改用相同功能的IN運算子或可以適當的利用聯集(UNION)作為改善。
例如,要找出公司內姓張、王、林的員工資料,使用OR運算子的SQL查詢指令如下所示:
SELECT FirstName, LastName, Title
FROM EMPLOYEE
WHERE LastName = '張'
OR LastName = '王'
OR LastName = '林'
改用相同功能IN運算子的SQL查詢指令,如下所示:
SELECT FirstName, LastName, Title
FROM EMPLOYEE
WHERE LastName IN ('張','王','林')
4. 適當地使用子查詢(Subquery)
子查詢可分為「獨立子查詢」(Uncorrelated Subquery)和「關聯子查詢」(Correlated Subquery),不管哪一種子查詢都會影響查詢效率。獨立子查詢是指子查詢的內容可以單獨被執行,亦即內層查詢會一次跑完後得到結果再給外層查詢引用。相反地,關聯子查詢則無法單獨被執行,亦即外層查詢的「每一次」查詢動作都需要引用內層查詢的資料,或內層查詢的「每一次」查詢動作都需要參考外層查詢的資料。所以若是使用關連子查詢,就要非常小心使用,因為它會隨著資料量的成長,效能會下降的非常快。
5. 盡量使用 OUTER JOIN + NULL 值的判斷
由於 Not In/ Not Exists 需要運用子查詢,較容易影響效能,再加上『負向查詢』(NOT)的判斷常會讓查詢最佳化模組無法有效地使用索引更是影響甚大。但是若將這些資料改用OUTER JOIN在加上判斷是否有NULL值就可以知道是否存在了。例如,找出公司內尚未調薪的員工資料,使用負向查詢的SQL查詢指令,如下所示:
SELECT E.ID, E.FirstName, E.LastName
FROM Employee E
WHERE E.ID NOT IN (Select ID From SalaryAdj)
改用OUTER JOIN 加上NULL值的SQL查詢指令,如下所示:
SELECT E.ID, E.FirstName, E.LastName
FROM Employee E LEFT JOIN SalaryAdj S ON E.ID = S.ID
WHERE S.ID IS NULL
6. 避免大量的排序操作
盡量避免使用ORDER BY、GROUP BY和HAVING子句的大量資料排序操作,因為操作排序會讓資料庫做額外的計算,增加處理時間,如果可能盡量避免使用。
7. 盡可能使用預存程序(Stored Procedure)取代直接存取資料表
預存程序是已經編譯的指令碼,因為不用再次編譯,對於大量資料交易或查詢的SQL指令而言,除了有顯著的執行效能,亦可節省SQL指令傳遞的頻寬,也可重複的執行。
結論
目前實務上遇到很多系統效能不佳的問題,很多都是因為應用程式對資料表的存取的SQL指令不當,導致資料處理的時間過長,造成網頁回應的速度過慢。其實,只要程式開發人員可以妥善地利用執行計劃來檢測自己所撰寫的SQL指令法的適當性,就可以避免這樣的問題一再地發生,亦可以協助自己對SQL指令的優化。