作者:楊剛仲/ 中央研究院統計科學研究所博士後研究
前言
在資料科學社群,研究者常在自己的電腦裡安裝其他研究團隊釋出的軟體套件進行研究與測試。這些軟體套件往往更新快速,甚至不到半年就會有大改版。研究者一個沒注意,安裝新套件順便升級相依套件,自己寫的程式碼昨天可以跑,今天不能動的情況時有所聞。對此,資料科學社群的研究者們在這幾年已慣於使用Anaconda建立隔離的研究測試環境,降低軟體版本衝突的影響。除了使用Anaconda之外,社群上亦有些研究團隊,將開發的軟體套件打包成容器映像檔釋出,研究者們只需要在自己的電腦下載Docker軟體,執行映像檔,省去一系列複雜的軟體安裝步驟,即可快速的在隔離的環境中進行研究測試。Anaconda與Docker的差異,有興趣的讀者可自行網路搜尋,在此先不展開。
讓我們從個人使用轉換到小型實驗室場景。實驗室裡研究者們多人共用一台計算能力強大的伺服器進行各自的研究。然而,以一般使用者權限,是沒有辦法自由配置容器的(這關係到伺服器資源配置的權限)。換句話說,研究者在自己的電腦上,原本可以自己參照網路教學,執行容器環境(因為研究者對自己的電腦有完整的權限),今天要把套路搬到實驗室伺服器上,變成要請伺服器管理者幫忙分配資源,啟動容器。如果容器配置經常更刪變動,研究者勢必頻繁的召喚伺服器管理者,增加彼此負擔。有沒有什麼簡單的方案(對研究者與伺服器管理者都友善),可讓研究者用一般使用者權限帳號,也可以管理、部屬自己的容器環境呢?有的,這就是今天要介紹的 Podman rootless mode。
Podman簡介
Podman跟Docker一樣是個容器管理程式。Podman在 RHEL 8 與 CentOS 8是預設的容器管理程式,RHEL 7.7以上亦可以安裝。Podman的指令與Docker高度相似,方便 Docker使用者可以無痛轉移到Podman平台。Podman有個與 Docker很不相同的特色,就是Podman 是daemonless,不需經由守護程式管理容器運行。對一般伺服器使用者而言,最明顯的差別就是,利用top觀察實驗室裡有誰在競爭運算資源的時候,如果容器是用Docker管理的,只會看到一堆由Docker身分代行的程式;如果是用Podman管理容器,則可直接看到是那個使用者在競爭運算資源。Podman rootless mode更是由使用者帳號自己管理自己的容器倉庫,伺服器管理者也不用擔心由使用者帳號執行的容器會有越權問題。
以Podman建立多版本GPU運算環境,伺服器管理者端
接下來,我以小型實驗室購買了配備數張GPU卡的伺服器供研究室成員使用為場景,介紹如何使用podman rootless mode建立由研究者自行管理之多版本GPU運算環境。
首先,伺服器管理者在伺服器上應先完成的設定如下:
1. 根據顯卡型號,安裝最新的NVIDIA 驅動程式,驅動程式有向下相容,裝最新的即可。安裝完成後,執行nvidia-smi,應該要能看到系統列出多張顯示卡的畫面(圖1)。
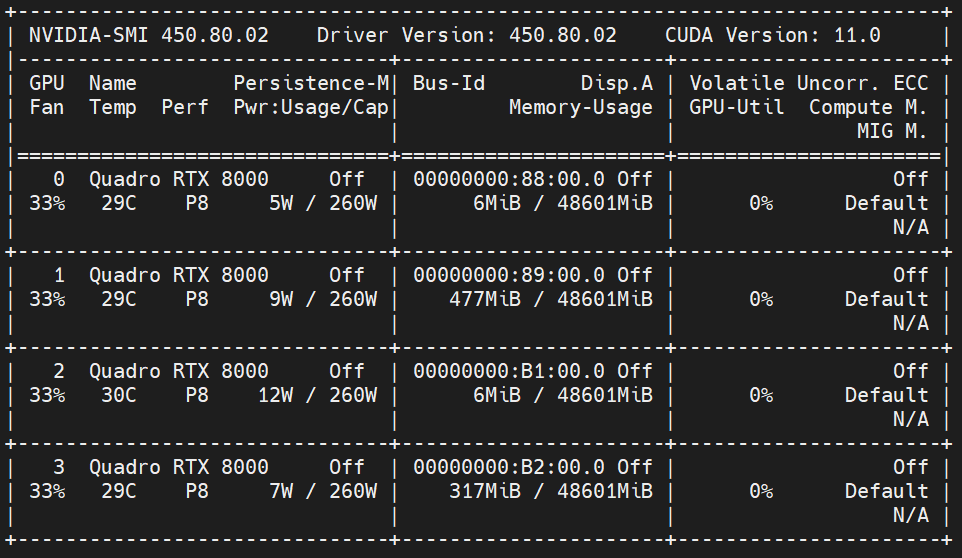
圖1:nvidia-smi 輸出結果。上列顯示安裝的驅動版本,以及連帶安裝的CUDA版本,以及有4張GPU被偵測到。
2. 安裝 NVIDIA Container Toolkit。NVIDIA Container Toolkit包含了一些執行cuda容器時需要的函式庫與工具。這裡我們借用官網 Github的示意圖,讀者可以看到,圖中最上面,不同的容器可以由一些固定的小元件堆疊組合而成,我們要創造一個可呼叫GPU的容器,需要安裝 NVIDIAContainer Toolkit。
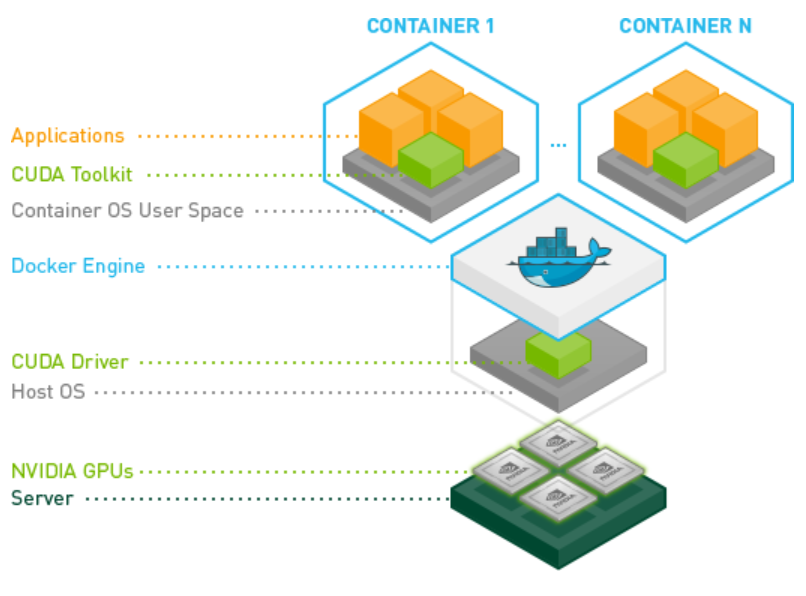
圖二:NVIDIA Container Toolkit (from: https://github.com/NVIDIA/nvidia-docker )。
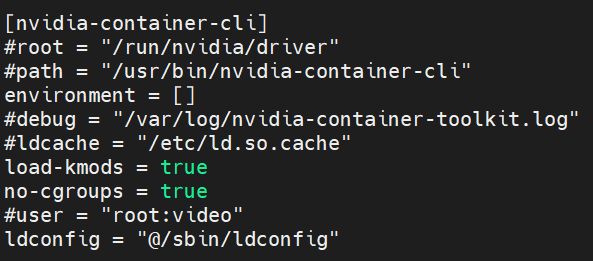
3. 修改NVIDIA Container Toolkit設定檔。要讓研究者以一般使用者身分執行cuda容器,伺服器管理者需要修改NVIDIA Container Toolkit設定檔。將no-cgroups改成true。 設定檔位置在/etc/nvidia-container-runtime/config.toml。
4. 防火牆開洞。研究者建置開發型容器,有很高的機率會使用 Jupyter 或 tensorboard 等網頁程式,伺服器管理者應預先在防火牆上開放一些高號碼的埠口,再將這些埠口分配給研究者(一個研究者配10個port之類的)。
伺服器管理者完成以上工作之後,研究者即可依自身需求,自行建置與管理不同版本的CUDA容器了。
以Podman建立多版本GPU運算環境,研究者端
研究者以一般使用者身分登入伺服器後,已經可以自行建置或是引用別人的容器環境了(而且可以建立多個)。以下介紹一般使用者如何自建一個可呼叫GPU的開發型容器:
1. 從 Docker hub “nvidia/cuda” 官方倉庫下載包含特定cuda版本的OS映像檔(例如:包含 cuda11 與 cudnn8 的 centos8)。
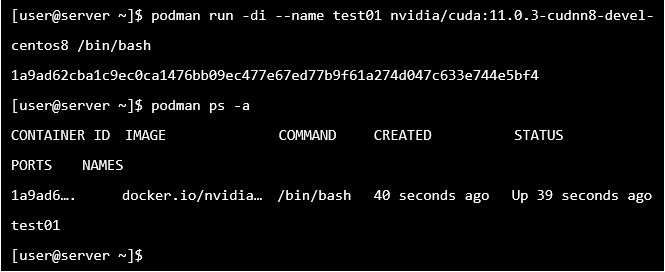
開發型容器強烈建議使用 devel 版本當起始範本,之後安裝才不會因缺檔而報錯。以上指令可讓一般使用者啟動一個可提供登入的cuda容器,並將容器取別名為 test01,以及預先執行 bash 程序 (不然容器會因為沒有程序在持續執行而立刻結束)。
2. 進入容器互動模式,確認能不能成功呼叫到CUDA。
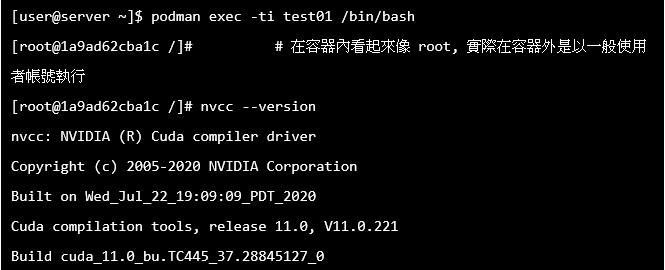
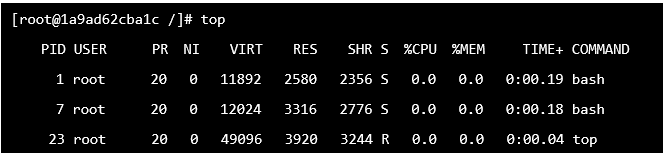
3. 也可以top一下,看看這個容器內執行的程式。PID最小的bash是為了不要讓容器關掉,一開始常駐執行的,第二個bash是剛剛登入執行的。
4. 接下來研究者可自己update system(很重要,nvidia/cuda 官方倉提供的OS非常精簡,不更新的話可能會缺基礎套件,導致後須安裝出現奇怪的錯誤),安裝anaconda,在anaconda 中開新環境,安裝jupyter, tensorflow等軟體套件。
5. 在容器裡安裝完需要的軟體與套件之後,可以退出打包剛剛辛苦安裝的成果,常用的指令如下(與 Docker 指令相同):
| 指令 |
功能 |
| podman images |
列出使用者自己管理的容器映像檔 |
| podman ps -a |
列出使用者自己運行的容器 |
| podman stop aliasname |
停止執行中的容器 |
| podman commit aliasname imagename |
打包成映像檔 |
| podman rm aliasname |
移除非執行中的容器 |
6. 打包完成,研究者可重新載入自己剛製作的映像檔,順便開啟埠口(管理者分配的),掛載資料夾,設定環境變數等,以下提供範例:

結語
以上範例介紹了在小型實驗室中,伺服器管理者如何配置一個足夠彈性的容器平台,提供實驗室研究者自行建置、管理或使用別人的容器映像檔,不用擔心某個不明的映像檔把容器服務搞垮了,或是異常提升權限造成系統漏洞;研究者們在使用伺服器上的資源時,也可以獲得如使用自己電腦般的舒適體驗。從此,實驗室大夥,再也不用載擔心別人把自己的研究環境弄亂了,一家和樂,可喜可賀。