作者:周秉誼 / 臺灣大學計算機及資訊網路中心作業管理組碩士後研究人員
計資中心為了提昇原有高效能運算的運算能力,在今年建置了一套圖形處理器叢集,以CUDA圖形處理器運算環境提供高效能運算服務。圖形處理器中,有大量處理核心,可同時處理不同運算工作。研究人員可以利用CUDA的C語言擴充,直接用C語言寫程式,在圖形處理器上進行科學運算,充分發揮圖形處理器強大的運算能力。
前言
現代的視窗系統通常都有許多華麗的3D效果、電腦遊戲中也有許多3D特效來呈現特別的招式及場景的壯闊,為了流暢地把這些內容展現在電腦螢幕上,現在的電腦通常都配備了顯示卡或整合性的顯示晶片,來加速處理影像繪製及螢幕輸出。OpenGL及Direct3D等API (Application Programming Interface) 也讓電腦遊戲的繪圖工作更方便,可以繪製更複雜的效果。為了繪製更精緻的材質和複雜的效果,繪圖所需的運算能力也隨之提高,顯示卡核心晶片的運算能力也如同中央處理器 (CPU) 一般直線成長,甚至擁有不下中央處理器的運算能力,產生了圖形處理器 (GPU, Graphics Processing Unit) 這個概念。
因此需要大量計算能力的研究人員,就想到可以在每一台電腦都有的圖形處理器上面進行科學計算和模擬。過去的GPU主要負責圖形繪製,想要在圖形處理器上進行科學運算或一般類型的運算,就要使用GLSL (OpenGL Shading Language) 、CG (C for Graphics) 等著色器語言 (shading language)撰寫程式。程式在執行時,會將著色器語言的程式碼載入圖形處理器硬體的驅動程式,再利用OpenGL或其他API把程式碼編譯為GPU可識別的機器碼在圖形處理器上運行。因此想要撰寫可在圖形處理器上進行一般運算的程式,是非常複雜而且麻煩的事情,很難有效率地調效程式。為了把中央處理器的運算工作,移到圖形處理器上進行,也就是通用型圖形處理器 (General-Purpose Graphics Processing Unit, GPGPU) 的運算概念,CUDA、OpenCL、DirectCompute等利用GPU運算的函式庫及API分別被NVIDIA、Microsoft等公司提出來。
CUDA運算環境
CUDA (Compute Unified Device Architecture) 是NVIDIA提出,可在NVIDIA圖形處理器進行平行運算的計算環境。程式設計者可以利用CUDA的C語言擴充 (extension) 直接用C語言寫程式,設計資料分配 (data decomposition) 及程式流程將運算工作分配到上千個執行緒(threads)及圖形處理器中數以百計的計算核心 (cores)。CUDA可以運作在NVIDIA GeForce 8系列之後的GPU上,現在常見的一張二千元的NVIDIA顯示卡,就能進行CUDA運算而且效能驚人,所以GPGPU也算是一種平價的高效能運算方式,它把桌上型電腦變成一台個人的超級電腦 (personal supercomputer in a desktop)。
在CUDA程式中,有兩個不同的運算環境:host及device。Host就是原本中央處理器的計算環境,可以讀寫檔案、配置記憶體、使用外部函式庫、呼叫和傳遞參數給GPU的副程式。Device是指GPU,它有獨立的記憶體和計算核心,計算用的資料需要從host傳送到device上的記憶體,才能在device中處理。在device上執行的副程式,稱為kernel,通常有上百到上千個執行緒(thread)執行同一個kernel。
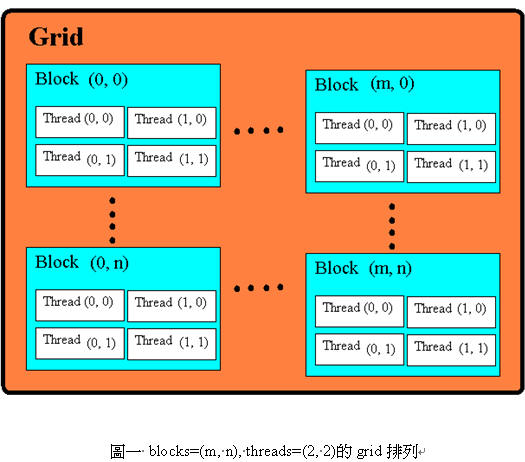
每一個執行緒會屬於一個執行緒區塊 (thread block),每一個block裡的thread總數有上限,不能超過512個thread,可以指定成一維到三維的排列方式。所有的block又會以一維或二維的方式排列在格子(grid)裡,每次Kernel要啟動的時候,就會以kernel_function<<<blocks, threads>>>(…) 語法,來宣告grid及block的排列方式。每個thread及block依不同的排列順序會有不同的編號 (thread/block ID),藉由執行緒編號,資料可以分配到不同執行緒上進行處理。圖一顯示一個blocks為(m, n)、threads為(2, 2)的grid,其中block和thread的排列方式。
圖形處理器硬體環境
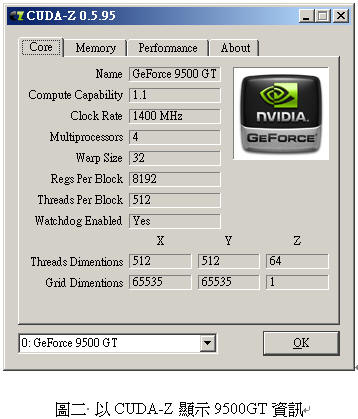
圖形處理器的硬體是由許多Streaming Multiprocessors (SMs) 及global memory組成。每一個SM裡還有數個Scalar Processors (SPs)、shared memory、指令提取分派 (instruction fetch/dispatch)、雙倍精度浮點數 (double precision unit) 等控制器。程式中的一個block會分配到一個SM上面執行,block中的thread會分配到這個SM的SP上執行,因此同一個block中的所有thread都可以看到共同的share memory區段,也可以進行同步指令 (synchronize)。以GeForce 9500GT為例,有4個SM、最高1GB的global memory,每個SM上有8個SP、16KB的share memory。圖二是以CUDA-Z軟體顯示NVIDIA 9500GT圖形處理器的資訊。
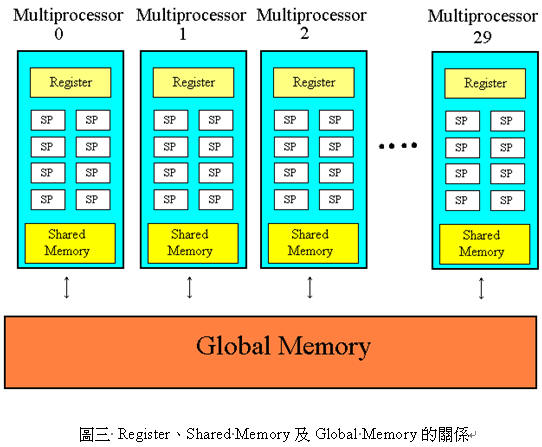
圖形處理器的記憶體類型有很多種;Global memory是由全部的block共用的,在host的環境中也可以存取得到;每個SM上的share memory是block內部共用,還有register讓每個thread存放資料。速度最快的是register,share memory在特殊的存取方式下,可以跟register一樣快,global memory最慢,存取所需時間是share memory的上百倍。在撰寫程式時,可以利用 __share__ 修飾符 (qualifier) 指定share memory,減少存取花費的時間。圖三顯示register、shared memory及global memory的關係。
圖形處理器有獨立的記憶體,在進行計算之前,host端程式需要以cudaMalloc()在device上的global memory配置記憶體,再用cudaMemcpy()搬移記憶體內容,在device上執行的kernel才能取得資料。如果要在global memory及share memory間移動,要在kernel裡搬移。計算結束後,把資料搬回host端,再用cudaFree()釋放記憶體。
CUDA程式跟C程式類似,撰寫完程式碼之後,都要先編譯 (compile) 之後才能執行。但是不太一樣的部份是,CUDA的kernel及device副程式都是在圖形處理器上進行運算,編譯器 (compiler) 會進行比較特殊的處理。一個副檔名是.cu的程式碼,編譯器會分成host及device兩個部份處理。host部份的程式碼就依一般的C程式的編譯方式,產生可執行的機器碼。而device部份的程式碼會由NVIDIA提供的編譯器,產生成PTX (Parallel Thread eXecution) 環境的組合語言 (assembly),在程式要被送到圖形處理器執行時,才被圖形處理器的驅動程式 (driver) 組譯成不同圖形處理器可以執行的機器碼。這種設計的好處是不用在編譯時就決定圖形處理器核心類型,可以相容不同型號的GPU核心,但也使得device程式沒辦法直接直接呼叫現成的函式庫,目前也還不支援函式遞迴呼叫 (recursive function call)。在使用nvcc編譯時加上-ptx可以產生PTX組合語言碼,加上-cubin可以產生kernel程式使用register、shared memory的數量資訊,這兩種資訊對程式最佳化很有幫助。表一列出CUDA程式碼及對應的PTX程式碼、cubin資訊。

CUDA數學計算
為了方便科學運算,CUDA也將常用到的數學函數,如sin(),exp()等包裝進編譯環境裡,這些提供的數學函數就可以直接在device程式中呼叫。如果不需要那麼高的精確度,而是需要率效的話,也有圖形處理器內建的數學函數 (Intrinsic function) 可以使用,函數名就是原本的函數前加入底線,如 __sin()、__exp(),這些函數直接對應到GPU上的指令集,所以效率很高。常用來處理向量計算的BLAS (Basic Linear Algebra Subprograms) 及數位訊號處理、大數乘法的FFT (Fast Fourier Transform) 等,都有針對CUDA環境改寫,並整合在CUDA環境裡。
另外一個跟數學運算有關的限制是,目前圖形處理器的雙倍精度浮點數 (double precision float) 的運算能力,與單倍精度浮點數 (single precision float) 的運算能力落差很大,甚至較低階的圖形處理器還不支援雙倍精度浮點數的運算。雙倍精度浮點數的運算速度,在下一個版本的核心Fermi將有很大的增進,預期可達目前高階顯示卡的八倍。
GPU Cluster
計資中心為了提昇原有高效能運算的運算能力,在今年建置了一套圖形處理器叢集 (GPU cluster)。該cluster共有20個S1070圖形處理器,每個S1070圖形處理器有240個scalar processors,組成30個streaming multiprocessors。還有4 gigabytes的global memory、每個multiprocessor有16 kilobytes的share memory,浮點數的運算能力可達1035 gigaflops。
GPU Cluster使用Linux作業系統,及CUDA圖形處理器的運算環境。並使用PBS Pro排程軟體進行計算工作排程,確保每個計算工作都能有充足的計算資源可以使用,且不同計算工作間不會互相影響。運算節點間分享的檔案系統是lustre,比常見的NFS有更好的存取速度。
結論
圖形處理器的運算能力進步飛快,以大量處理核心加速運算的方式,更是領先傳統的中央處理器,尤其在中央處理器放棄追求高時脈之後、改走多核心提高效能的現在,更是顯示出圖形處理器開發人員的遠見,而圖形處理器中大量處理核心的架構,或許也有多核心處理器值得參考的地方。
圖形處理器在一般用途的計算上打開了一條新的路,顯示強大的運算能力也可以用在圖形處理之外的地方。除了CUDA,還有OpenCL、DirectCompute等程式介面,可用來撰寫圖形處理器的應用程式,顯示晶片及中央處理器的廠商也有整合中央處理器和圖形處理器的研發計劃,可以想見會有更多常見的應用程式直接使用圖形處理器進行計算。
等到目前圖形處理器在雙倍精度浮點數的劣勢,在NVIDIA新核心Fermi出現之後,得到加強,相信不久的將來,也會有圖形處理器組成的超級電腦,擠身在五百大超級電腦的列表中。